There has been a lot of hype around the newly announced Microsoft Fabric – the marketing machine surely did a very good job! But what if we take a look behind? Is this really as GINORMOUS as Kim Manis, Amir Netz, Arun Ulag says? Or is it just old wine in new bottles?
In many ways Microsoft Fabric is indeed Synapse Analytics version 2, but then there are also some rather big improvements. It’s defiantly not only a “SaaSification” and a new wrap around the services we already know and love.
Here are four of the main things that I am most trilled about.
Simplified architecture and infrastructure
For the last 5 years, I have been teaching an applied “Azure BI” training course. It have changed a lot throughout the years as the technology and services have evolved. It’s been super interesting for me, as I had to be on the beat, but at the same time make it very practical with a case story, so the students had a fully functional solution at the end of the training.
We have always used a lot of time and energy on setting up the infrastructure and the security. Making sure the different Azure services could communicate and exchange data. This has also made the most “noise” with the labs, when a student didn’t get the service principal etc. configured right.
With Microsoft Fabric, we can focus much more on the functionality and spend even more time getting practical with the labs and the case study. There of course is stil a need to focus on using best practice security, but it will be much simpler and less confusing.
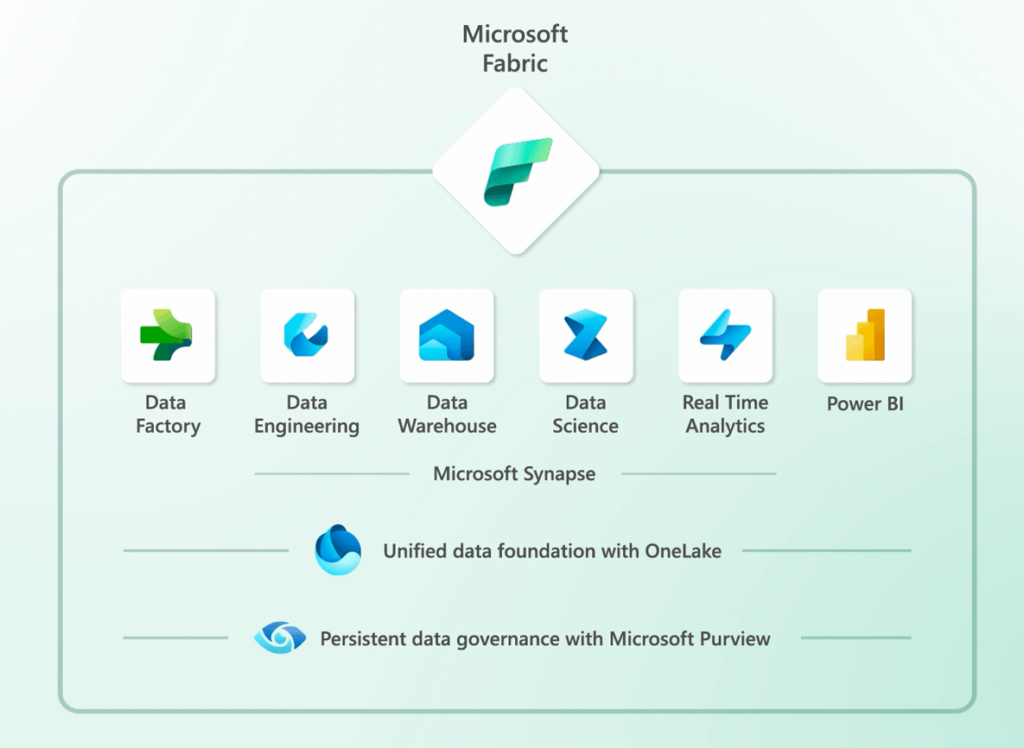
Delta Paquet in OneLake
This is another major change, that Microsoft have chosen the open-source Delta Lake as the underlying fileformat for all the compute engines. It makes a much more unified experience when handling and transforming the data. Finally we get a worthy replacement for the Common Data Model Folders, that Microsoft failed to introduce as the “new” fileformat 4 years ago. CDM folders was newer really implemented across the services and was mostly marketing and not really useful outside of Power BI dataflows. Time will tell if Microsoft gets it right this time – I choice to believe!
The combination with the OneLake concept is also really interesting. The name is maybe a little to much marketing?
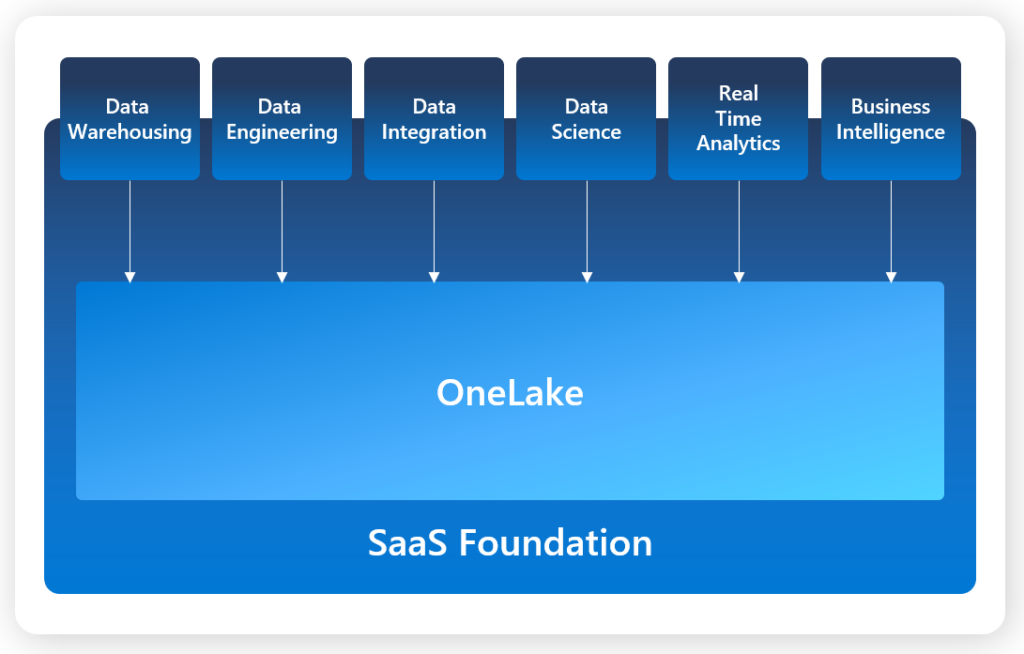
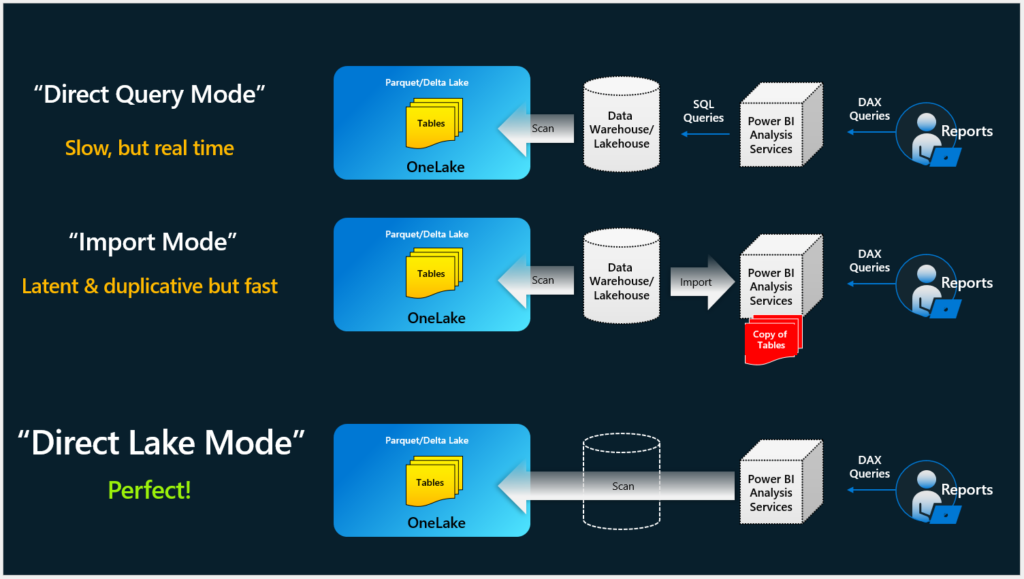
Direct Lake Analysis Services storage mode
Wow – just wow! For years and years we have had two main storage formats in Analysis Services. Back in the days it was called MOLAP and ROLAP and now we know it as Import and Direct Query. Then you could make a combination – known as HOLAP and Composite Models. But now we get a totally new storage format – or is it?
Power BI Premium has always been doing “evections” of datasets, when they haven’t been used for some time. The dataset is paged from memory to disk and then brought back into memory, when queries comes in again – without users noticing. A really clever memory saving technic that Microsoft now expanse on with the “Direct Lake Mode”, where the files on disk will be stored in Delta Parquet format. It’s essentially a VertiPaq format just like the Analysis Services Tabular engine – or should we call it VertiPaquet?. This means the files can be brought directly into memory – without the need to do a refresh operation.
The concept is then actually really simple. Specially in scenarios where you need near-real time data or where the data volumes is really really big. As Delta Parquet is the default fileformat in Fabric, you just need to generate the proper dimensions and fact as the end of your ETL process.
Enterprise ready Power Query for low-code ETL
I’m a big fan of writing my transformations with SQL code, but also see a lot of scenarios where a more low-code approach could be handy. It’s nice to see that Microsoft will make Power Query the next generation tool for low-code ETL as it has been used inside Power BI for many years. But will it be enterprise ready this time? The Wrangling dataflows as part of Azure Data Factory never lived up to the promise and lacked soo many features so it become useless. Making Dataflow a first class citizen in Fabric will indeed help the “transfer of ownership” story, when going from a self-service solution to a enterprise solution.
Another strong point of Power Query is the waist amount of connectors, that can be used as part of the ingesting phase. A lot can be done with Data Integration Pipelines, but sometimes you need an alternative to make a simpler integration.
I’m very curious for the future of Mapping Dataflows from Data Factory and Synapse Analytics? It doesn’t seem to be part of Fabric and will then get a slowly dead? I always been very skeptical about Mapping Dataflows and thankfully never implemented it in any solutions.