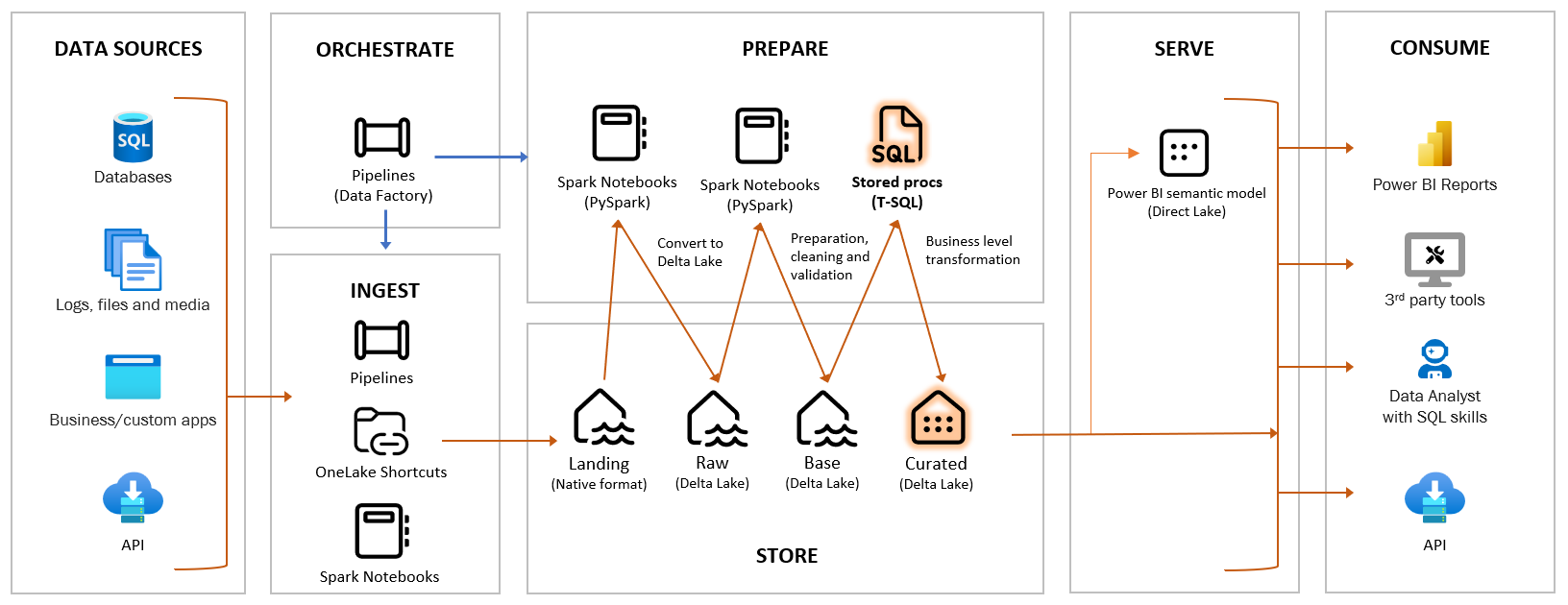
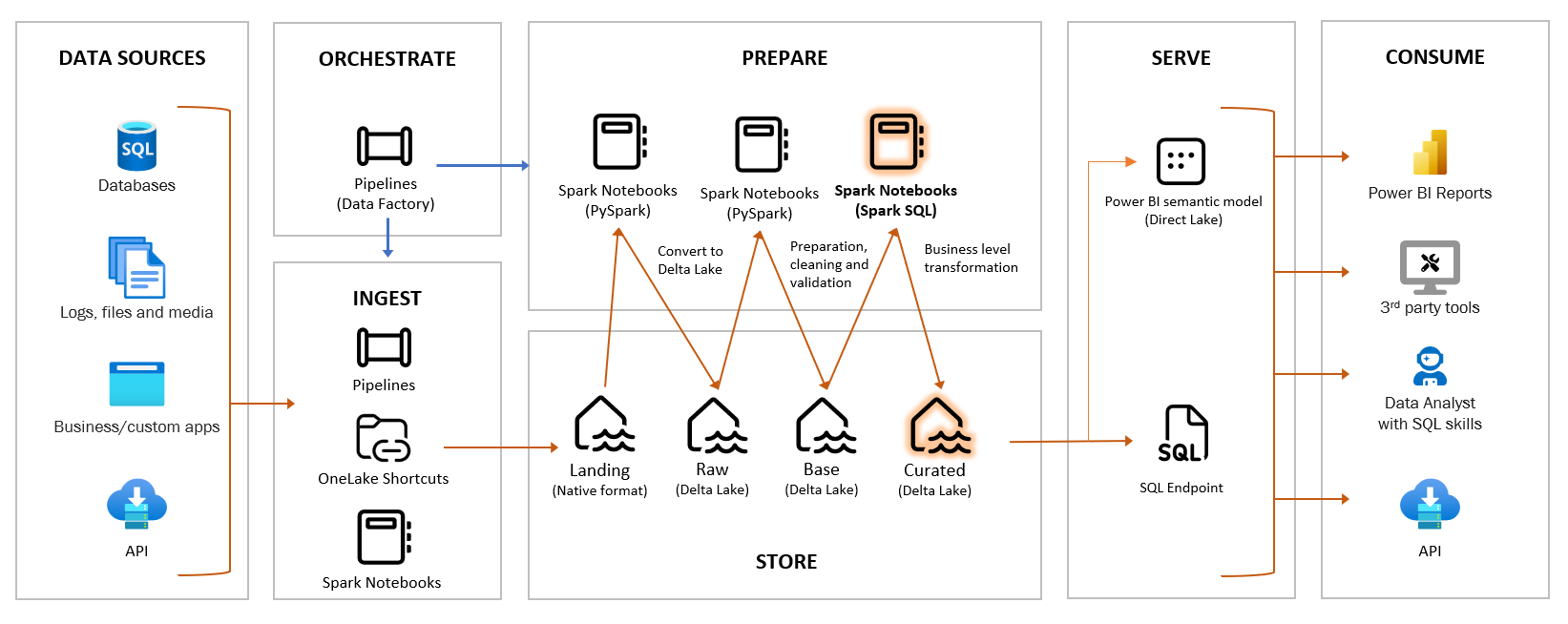
I come from a background in Business Intelligence and Data Warehousing on SQL Server and Azure SQL DB. In the past year, I’ve had many discussions and fielded numerous questions during courses, conferences, and conversations with colleagues. The topics range from understanding the buzz around Data Lakehouse to questioning the concepts of Bronze/Silver/Gold distinctions. There’s also the looming question of whether it’s time for everyone to learn Python, and, of course, the enduring relevance of good old SQL.
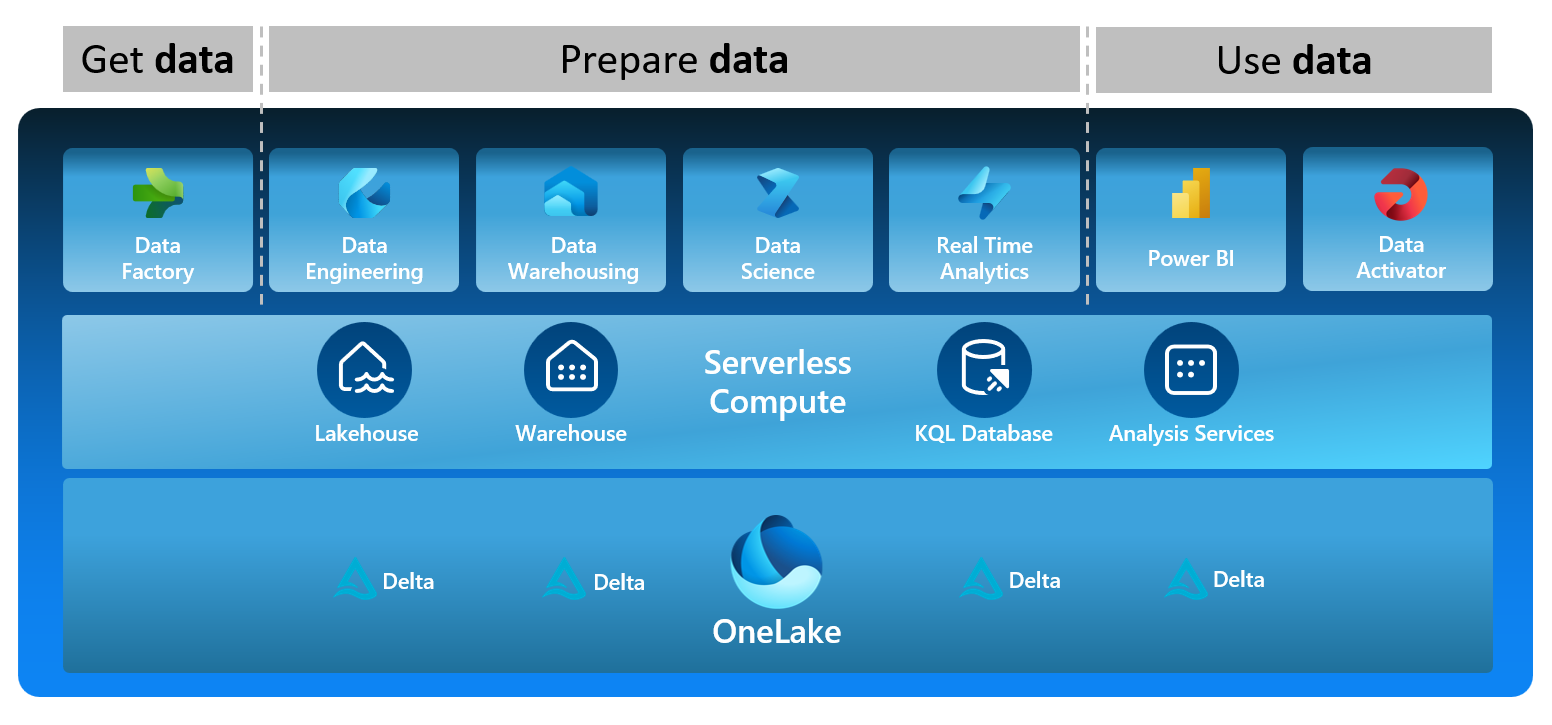
Demystifying Storage/Compute Decoupling
In the ever-evolving landscape of data management, the concept of decoupling storage and compute has emerged as a game-changer. This paradigm shift not only minimizes costs but also enhances flexibility, allowing for efficient scaling based on specific job requirements.
Minimizing Costs
The driving force behind the decoupling strategy lies in the stark contrast between the costs of storage and compute. While storage comes at a relatively low price, compute can be a significant expense. Decoupling enables organizations to pay only for the computing resources they use. This cost-effective storage approach provides the freedom to preserve historical data from source systems without breaking the bank.
Increased Flexibility
Decoupling opens the door to unparalleled flexibility. Computing resources will automatically be scaled up or down based on the demands of a particular task or job. Fabric capacities offers the “Bursting” functionality, that allows a job to use extra compute resources and go beyond the limit. This agility ensures optimal resource allocation, preventing unnecessary costs and delays.
OneLake Takes It a Step Further
Enter OneLake, a solution that not only embraces the decoupling philosophy but takes it a step further, addressing the complexities of both structured and semi-structured data. OneLake facilitates seamless collaboration across projects and departments by allowing the Spark, SQL, Kusto and Analysis Services compute engines to read and write to the same storage layer.
Delta Lake: The Magic Below the Surface
At the heart of this decoupled architecture is Delta Lake, an open-source storage framework that acts as the magic wand – or perhaps the magic fishing rod, given the analogy. Delta Lake extends the capabilities of Parquet data files by introducing a file-based transaction log. This brings forth the power of ACID transactions and scalable metadata management.
Delta Lake doesn’t stop there – it offers the enchanting ability of “Time Travel.” Organizations can journey back to previous versions of data, facilitating revisions, rollbacks, and a host of other historical data explorations. This feature adds a layer of resilience and adaptability to the data management strategy.
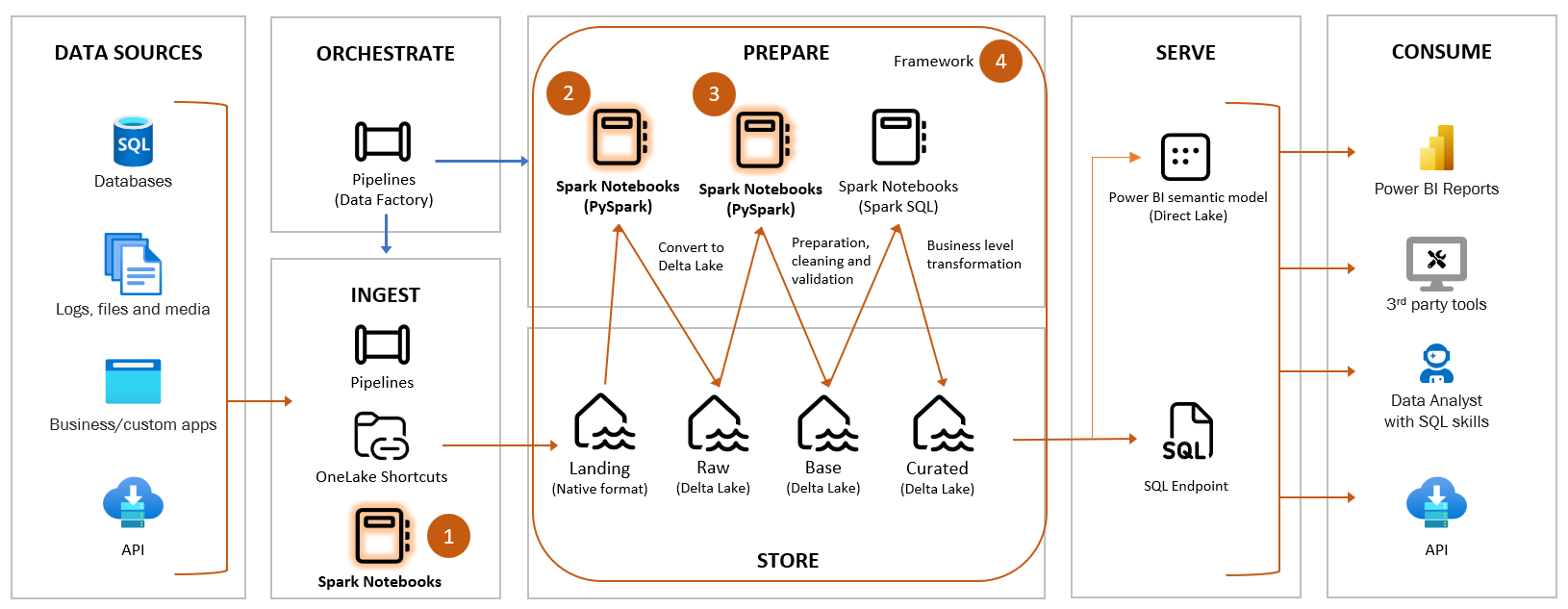
Demystifying PySpark
PySpark can be intimidating, and trust me, I’ve been there too! However, it’s crucial to understand that the intimidation is just the first step. The key is to use PySpark where it makes sense. Here is four scenarios where PySpark proves its worth, making it an essential tool in your Data Lakehouse toolkit.
Scenario 1: Integration with API-Based Sources
One powerful application of PySpark is its seamless integration with API-based sources, especially useful for handling event streams. By leveraging the input from an API call, PySpark can efficiently loop over and invoke another API. This scenario opens up a world of possibilities and is complemented by a plethora of libraries at your disposal.
Scenario 2: Handling Semi-Structured Data with Ease
Dealing with semi-structured data, such as JSON, XML, or Excel files, becomes a breeze with PySpark. Transforming this data into Delta tables provides the advantage of converting files into structured tables while imposing a schema on the data. This process, often termed “Files to Tables,” simplifies the management of diverse data formats.
Scenario 3: Automated Data Cleaning and Validation
PySpark’s capabilities extend to automating data cleaning and validation, which can be driven by metadata. With a myriad of Python libraries available, PySpark allows you to create a metadata-driven approach to ensure data quality and consistency.
Scenario 4: Breaking Free from SQL Constraints
Data Warehouse frameworks, whether simple or complex, typically rely on SQL Stored Procedures. While SQL can achieve incredible feats, it falls short as a programming language. Enter Python and PySpark! From handling Type 2 history, incremental loads, surrogate keys to audit columns, PySpark empowers you to write dynamic, metadata-driven code more efficiently than SQL.
Demystifying SQL’s Cool Factor
In the ever-evolving realm of Data Lakehouse, one might wonder: Is SQL still relevant? The resounding answer is yes, and not only is it relevant, but it’s also undeniably cool. Let’s explore why SQL remains a powerhouse in the world of data, seamlessly blending tradition with modernity.
SQL: Where Business Logic Finds Its Home
Defining business logic in SQL continues to be a best practice. Especially in the final stages of transformations, where dimensions and facts come to life, SQL proves its mettle. Its simplicity and versatility make it an ideal language for encapsulating business rules.
Portability Across Platforms and Cloud Providers
One of SQL’s enduring strengths is its ability to simplify the porting of logic between platforms and cloud providers. Whether you’re working with traditional databases or cloud-based solutions, SQL provides a universal language that transcends boundaries.
Harnessing the Skills of SQL Aficionados
Many Data Warehouse and BI developers boast impressive SQL skills. The transition to modern technologies doesn’t mean abandoning this expertise. Enter Spark SQL, a close cousin to T-SQL, enabling developers to leverage their SQL prowess in a contemporary environment.
Notebooks: Where SQL Meets Documentation
The integration of SQL into notebooks introduces a dynamic element to the equation. Now, alongside your SQL code, you can embed markdown for detailed descriptions and comprehensive documentation. It’s a synergy of code and context, fostering better understanding and collaboration.
Exploring Fabric Data Warehouse Items
For those venturing into the world of Fabric Data Warehouse items, the SQL engine remains a familiar companion. T-SQL stored procedures are still applicable, offering a seamless transition for those migrating from SQL DB-based Data Warehouses. It’s the best of both worlds – the power of SQL within the innovative Fabric framework.