This is the third post in my series on Fabric Spark Notebooks and CU consumption. In Part 1, we covered the fundamentals of CU consumption in Fabric Spark notebooks. In Part 2, we explored running multiple notebooks on the same capacity and how Fabric handles concurrency, bursting, and job queueing.
Now, we’ll focus on High Concurrency Mode, a feature that allows multiple notebooks to share the same Spark session. This reduces redundant compute allocation, improves execution time, and helps optimize CU usage.
Why High Concurrency Mode?
By default, each Fabric Spark notebook runs in its own isolated session, which means:
- Every notebook execution creates a separate Spark session.
- Running multiple notebooks simultaneously allocates multiple Spark clusters, consuming more capacity.
- This can quickly lead to hitting compute limits, unnecessary CU usage, and longer startup times.
High Concurrency Mode addresses these challenges by allowing multiple notebooks to share the same session, making execution more efficient.
How to Enable High Concurrency Mode
Fabric defaults to Standard Sessions, but you can switch to High Concurrency Mode directly from the notebook toolbar.
Steps to enable High Concurrency Mode
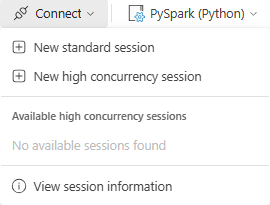
- Open a Fabric Spark Notebook.
- Click “Connect” in the notebook toolbar.
- Select “New high concurrency session” instead of “New standard session.”
- If an active high concurrency session exists, you can connect to it instead of creating a new one.
Once enabled, multiple notebooks can attach to the same Spark session, reducing startup time and optimizing compute usage.
Using High Concurrency Mode in Pipelines
High Concurrency Mode isn’t just useful for interactive workloads—it can also be configured in Fabric Data Pipelines to ensure multiple notebooks reuse the same Spark session.
Why Use High Concurrency Mode in Pipelines?
- Reduces redundant session startups, optimizing CU usage.
- Speeds up execution by attaching notebook activities to an existing session.
- Improves capacity efficiency when orchestrating multiple notebooks.
Configuring Session Sharing in Pipelines
Fabric Pipelines allow notebooks to share a session tag, ensuring they execute in the same high concurrency session.
Steps to configure session sharing in Pipelines:
- Add a Notebook activity to the Pipeline and select your notebook.
- In Advanced settings, locate the Session tag field.
- Assign a custom session tag (e.g.,
"pipeline_session"). - Use the same session tag for all subsequent notebook activities that should share the session.
With this setup, Fabric ensures that notebooks with the same session tag reuse the same high concurrency session, avoiding unnecessary compute allocation.
How High Concurrency Mode Optimizes CU Usage
The biggest benefit of High Concurrency Mode is session reuse. Instead of each notebook launching a separate Spark session, multiple notebooks can run within the same compute environment.
Example Scenario: Running Multiple Notebooks on an F4 Capacity
F4 Capacity Specs:
- 8 Spark vCores (burstable up to 24 vCores).
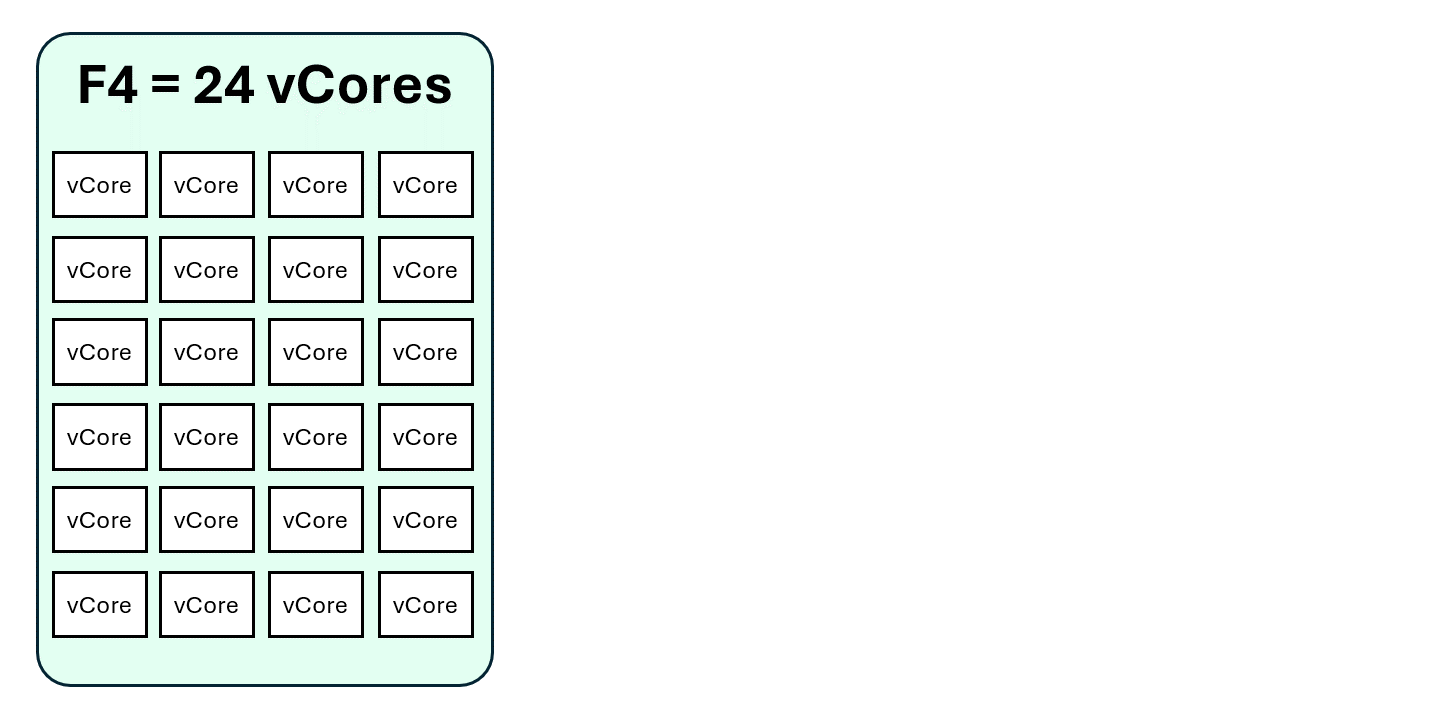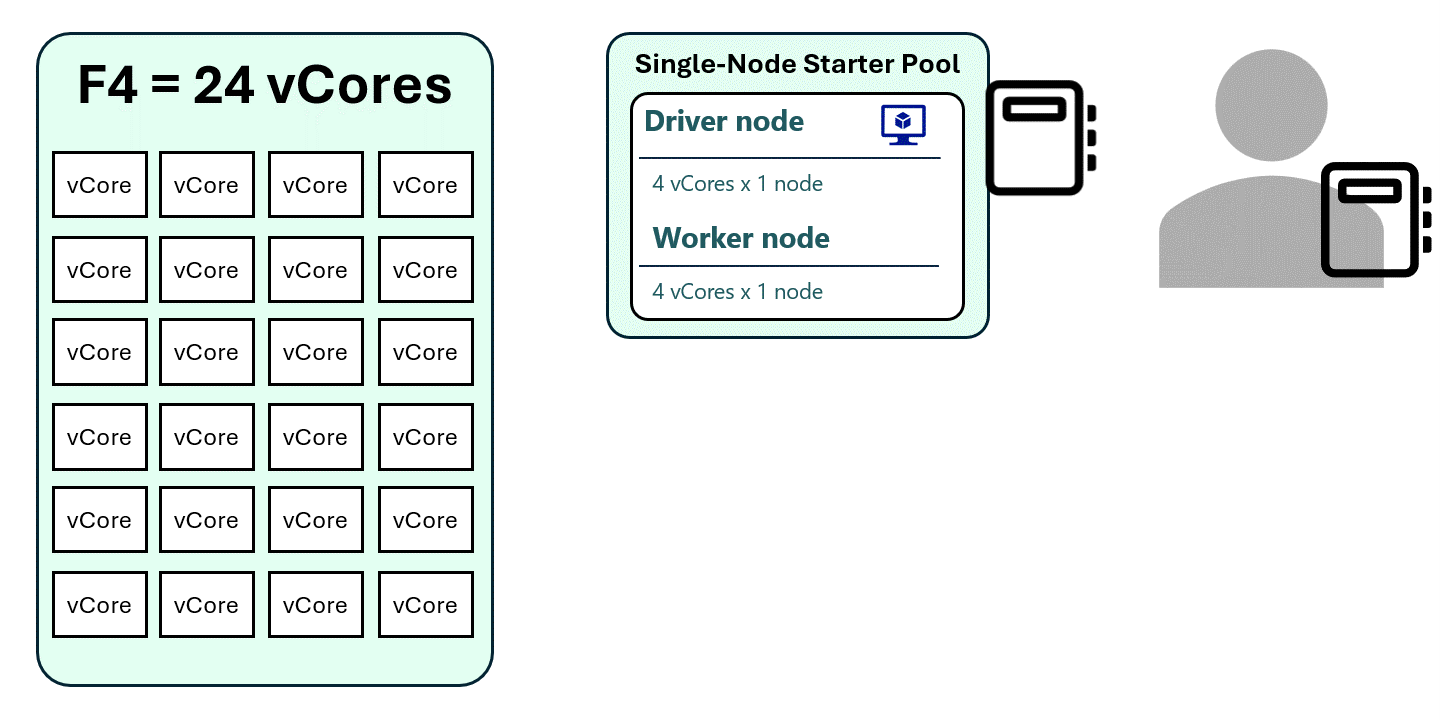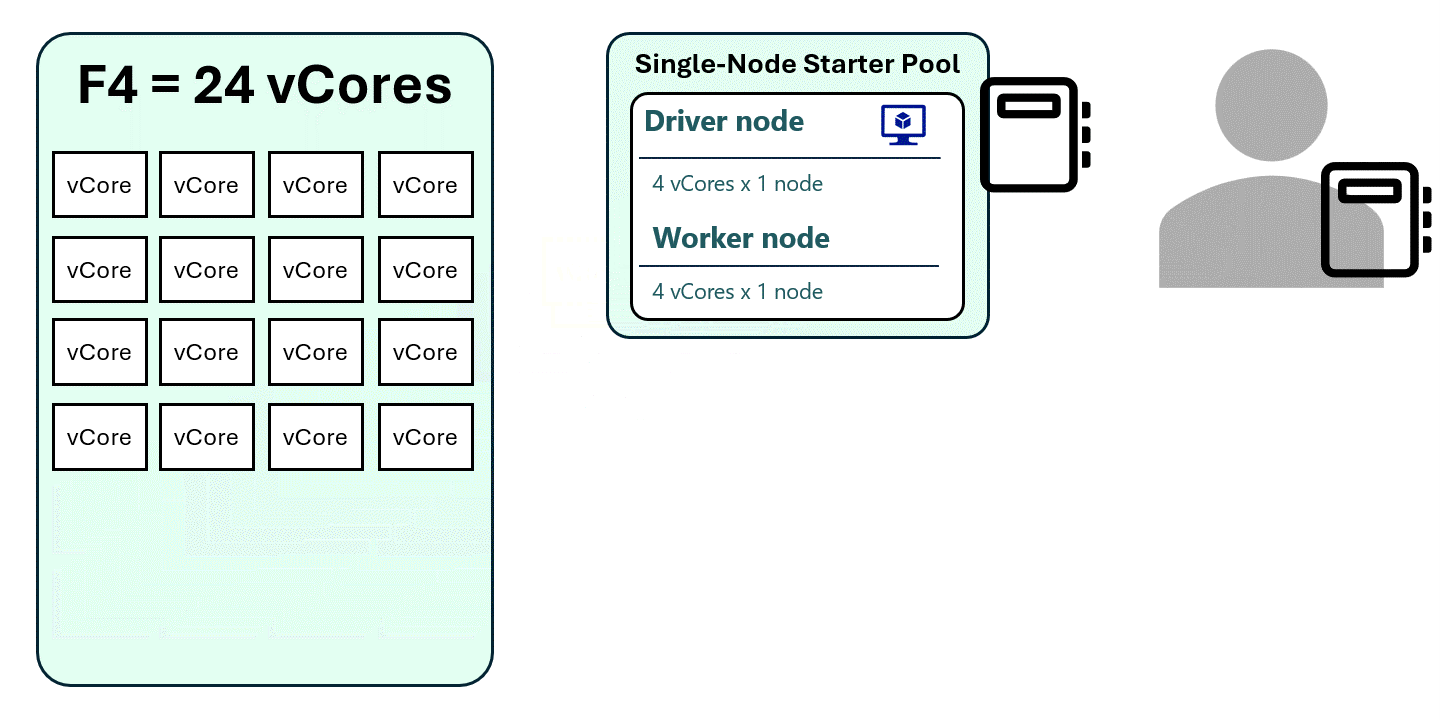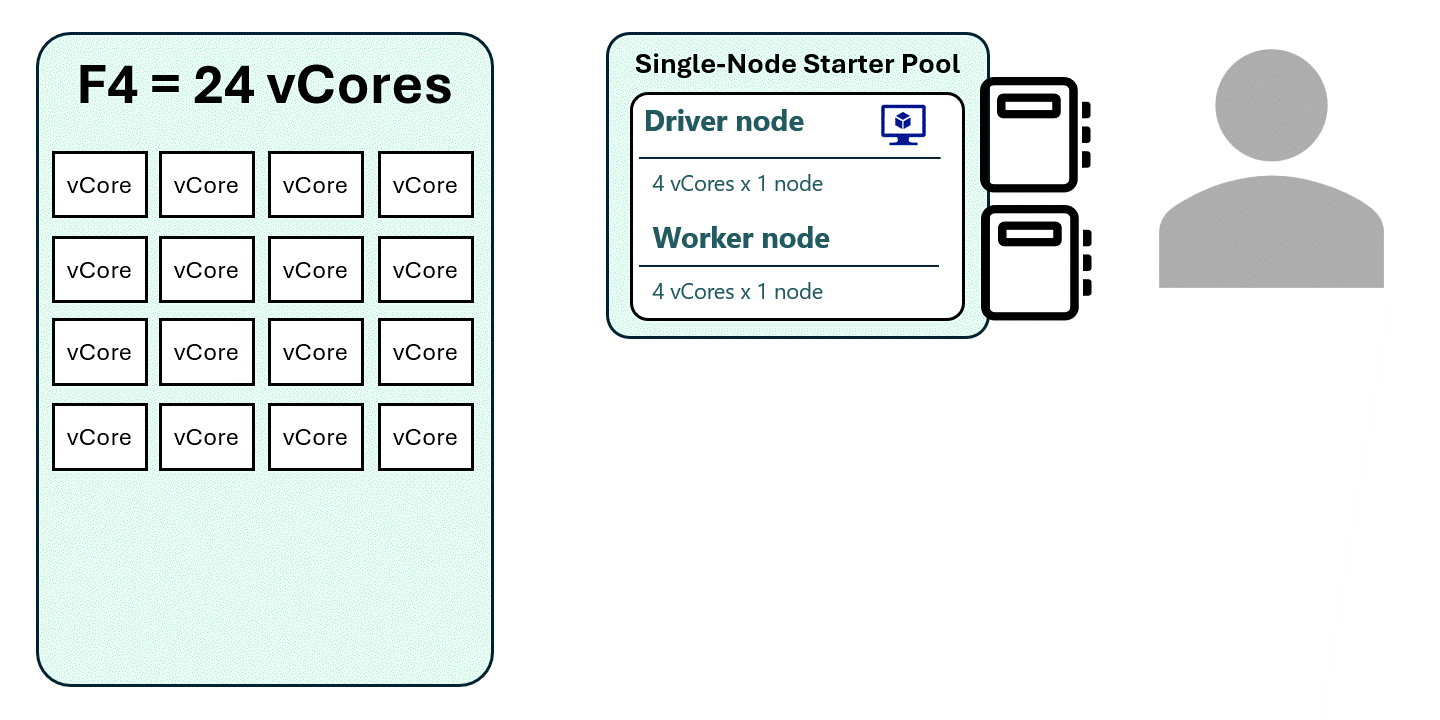
Without High Concurrency Mode (Standard Sessions)
- Each notebook runs in its own Spark session.
- A Medium Starter Pool session requires 16 vCores.
- On an F4 capacity, only one notebook session can run at a time.
- Additional notebooks hit capacity limits or get queued.
With High Concurrency Mode
- Multiple notebooks share a single Spark session.
- Three notebooks can run using one Spark session instead of three separate ones.
- This allows more notebooks to run concurrently on the same Fabric capacity.
Limitations of High Concurrency Mode
While High Concurrency Mode helps optimize compute resources, there are some limitations:
- Sessions are user-specific – They cannot be shared across different users.
- Notebooks must use the same default Lakehouse configuration – If different Lakehouses are referenced, separate sessions are created.
- Maximum of five notebooks can attach to a single High Concurrency session.
These constraints mean that while session sharing is effective, it does not function as a fully shared cluster across multiple users.
When Should You Use High Concurrency Mode?
Recommended Use Cases
- Running multiple notebooks interactively – Reduces session startup time.
- Iterative development where you frequently test different scripts.
- Optimizing capacity usage on smaller Fabric SKUs like F2, F4, or F8.
When Not to Use High Concurrency Mode
- Scheduled jobs in production – Isolated sessions may be better for workload separation.
- Different Lakehouse configurations – If notebooks reference different Lakehouses, they require separate sessions.
- Multi-user scenarios – Since sessions cannot be shared between users, High Concurrency Mode is not ideal for team-wide workloads.
| Use Case | Standard Session | High Concurrency Mode |
|---|---|---|
| Running a single notebook | ✅ Best choice | ❌ Not necessary |
| Multiple notebooks running concurrently | ❌ Each creates its own Spark cluster (high CU usage) | ✅ Notebooks share the same compute session |
| Interactivity & performance | ⚠ Slower startup time for each new session | ✅ Fast execution if a session is already active |
| CU optimization on limited capacity | ❌ Higher CU burn | ✅ More efficient CU usage |
Using RunMultiple to Control Execution Order
While High Concurrency Mode allows multiple notebooks to reuse a session, it does not define the execution order of those notebooks. If you need precise execution control, the runMultiple() function can help.
How RunMultiple Works
runMultiple() enables a parent notebook to trigger child notebooks in parallel or sequentially within the same Spark session. This ensures that execution follows a defined DAG (Directed Acyclic Graph) structure.
notebooks = [
{"path": "Notebook_A"},
{"path": "Notebook_B", "dependencies": ["Notebook_A"]},
{"path": "Notebook_C", "dependencies": ["Notebook_A"]},
{"path": "Notebook_D", "dependencies": ["Notebook_B", "Notebook_C"]}
]
notebookutils.notebook.runMultiple(notebooks)Why Use RunMultiple?
- Defines dependencies between notebooks.
- Enables parallel execution where possible.
- Reduces unnecessary session startups when orchestrating multiple notebooks.
For larger-scale orchestration, runMultiple() can be used alongside Pipelines or workflow tools to improve efficiency.
Key Takeaways & Best Practices
- Use High Concurrency Mode for interactive workloads to optimize CU usage and reduce startup times.
- Configure session tags in Pipelines to ensure multiple notebooks share the same session.
- Monitor active sessions to avoid unnecessary resource consumption.
- Understand the limitations – High Concurrency Mode is user-specific and supports up to five attached notebooks.
- Use RunMultiple for execution control, especially when orchestrating complex notebook workflows.
Final Thoughts & What’s Next
High Concurrency Mode is a powerful yet underused feature in Fabric Spark. It enables better resource utilization, reduces CU costs, and improves execution times, making it a valuable option for interactive and development workloads.
This is Part 3 of my Fabric Spark series. Next, I’ll be demystifying the monitoring of Spark in Fabric, covering:
- Monitor Hub
- Run Details
- Execution Breakdowns
- CU usage in Capacity Metrics
If you found this post helpful, let me know—how do you use High Concurrency Mode in your Fabric Spark workloads?
Pingback: Running Multiple Spark Notebooks on the Same Capacity – justB smart
Comments are closed.