Are you running multiple Spark notebooks in Fabric and wondering why you’re hitting compute limits?
Unlike other Fabric workloads, Spark assigns each user their own dedicated compute. This means resources are not shared between developers, and each active session consumes part of your Fabric capacity.
If you’re working on multiple notebooks yourself, or if multiple developers are running workloads on the same capacity, you may quickly run out of resources—even if your capacity still has CU available.
In this post, we’ll explore:
- How Fabric handles multiple Spark notebooks
- What happens when capacity limits are reached
- Bursting behavior and how it affects compute availability
- Strategies to optimize multiple Spark notebook sessions
If you haven’t read Part 1, I recommend checking it out first, as it covers the fundamentals of CU consumption in Fabric Spark notebooks.
Fabric Capacity and Bursting
Let’s take a simple example using an F4 capacity:
- F4 = 4 Capacity Units (CU)
- 1 CU = 2 Spark vCores
- F4 = 8 Spark vCores
Bursting: Using More Than 100% of Capacity
Fabric allows temporary overuse of capacity through bursting, meaning you can consume extra compute resources beyond what you have purchased.
Bursting Factor for Spark:
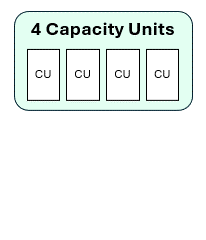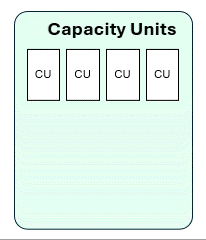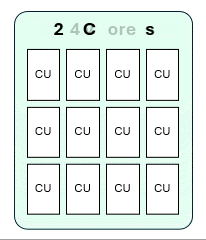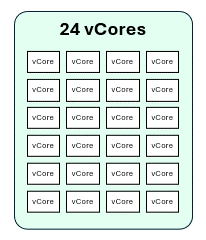
- F4 has a 3x burst multiplier
- This means F4 → 12 Capacity Units → 24 Spark vCores
Bursting helps with concurrent workloads and with a recent update now also increase the maximum cores available for a single Spark job.
To make it easier to compare, here’s a breakdown of how bursting applies to different Fabric SKUs:
| Capacity SKU | Base CUs | Base Spark vCores | Burst Multiplier | Max vCores with Bursting |
|---|---|---|---|---|
| F2 | 2 CUs | 4 vCores | 5x | 20 vCores |
| F4 | 4 CUs | 8 vCores | 3x | 24 vCores |
| F8 | 8 CUs | 16 vCores | 3x | 48 vCores |
| Trial Capacity | 64 CUs | 128 vCores | 1x | 128 vCores |
Exceptions to Bursting:
- Trial capacities do not offer bursting.
- F2 has a 5x burst factor, allowing it to scale from 4 vCores to 20 vCores
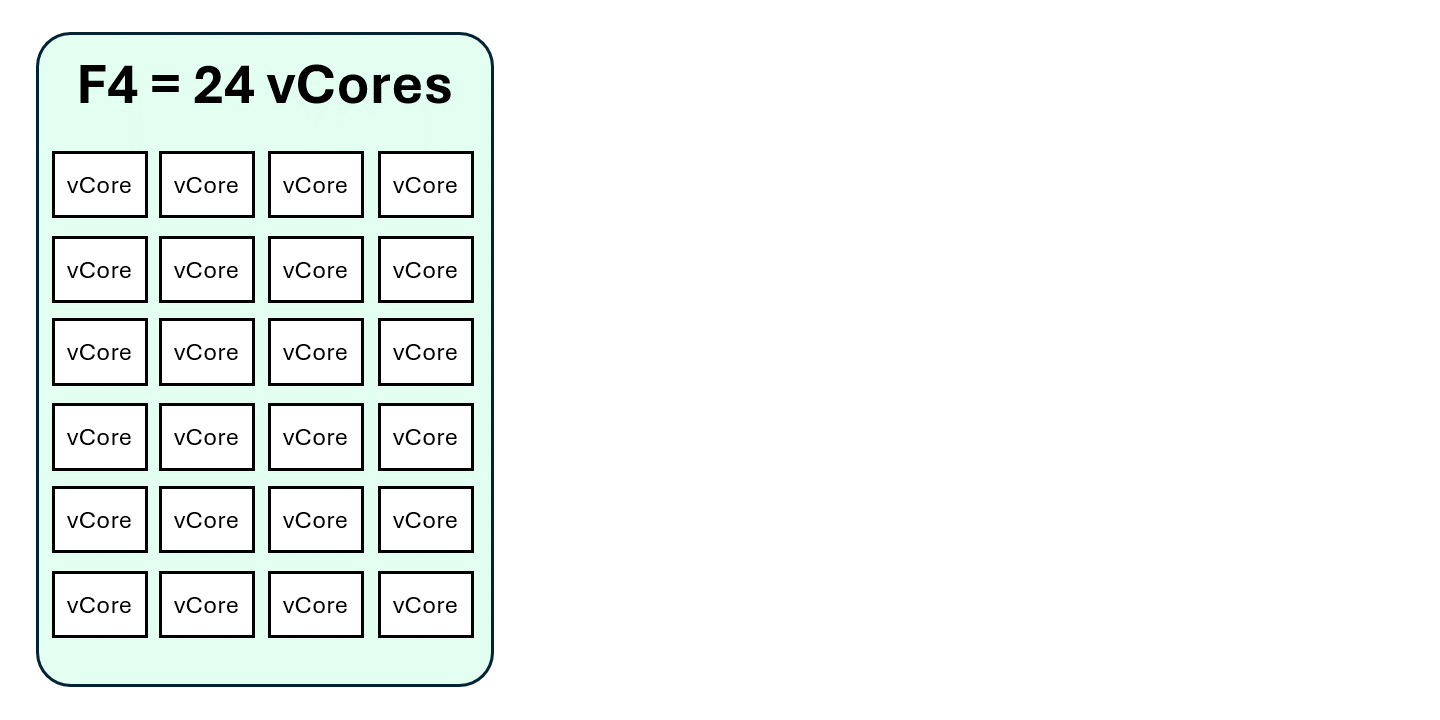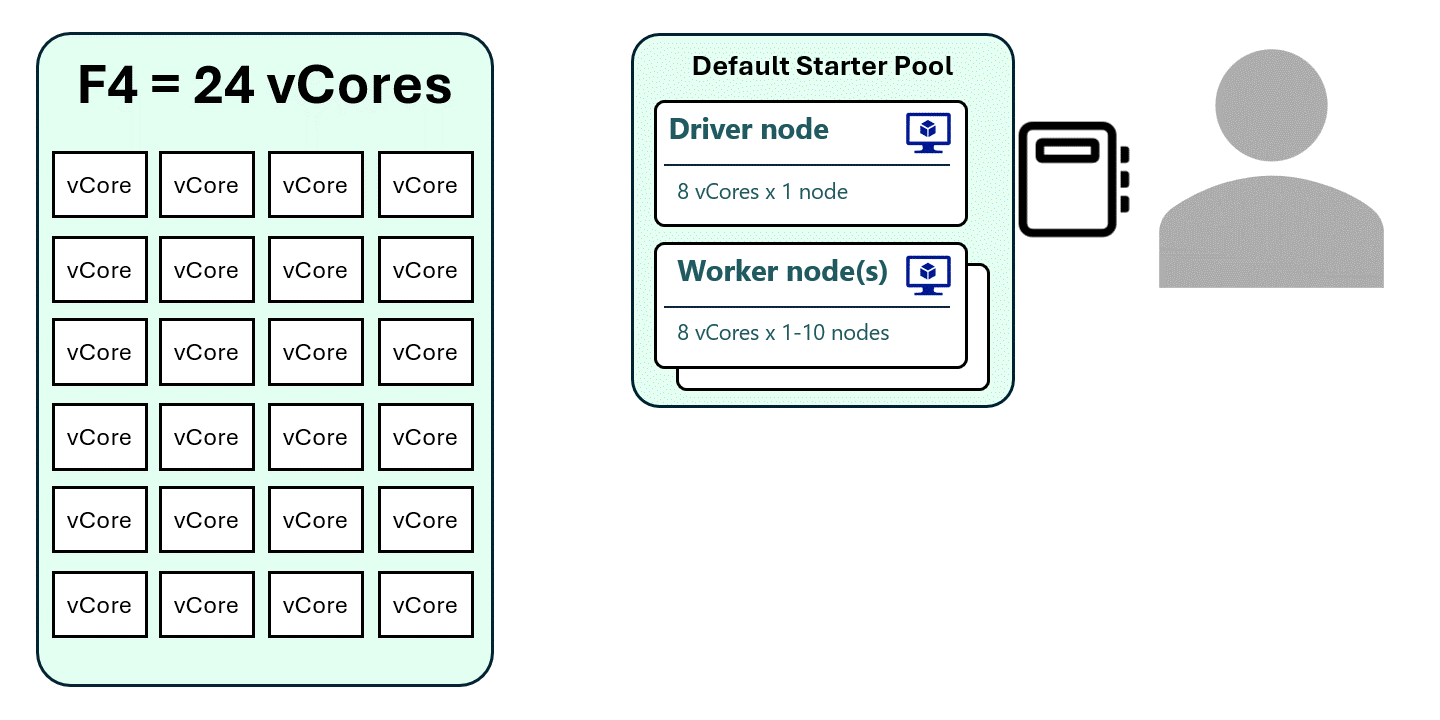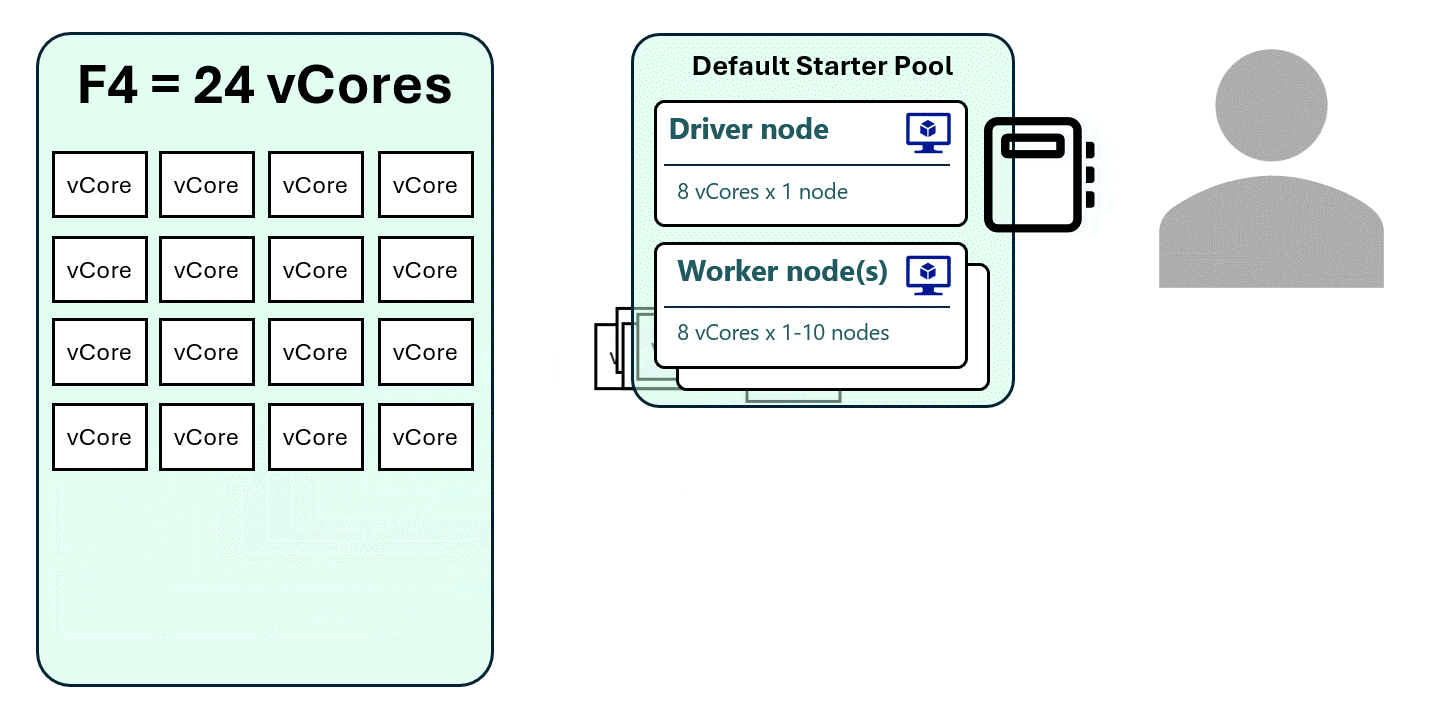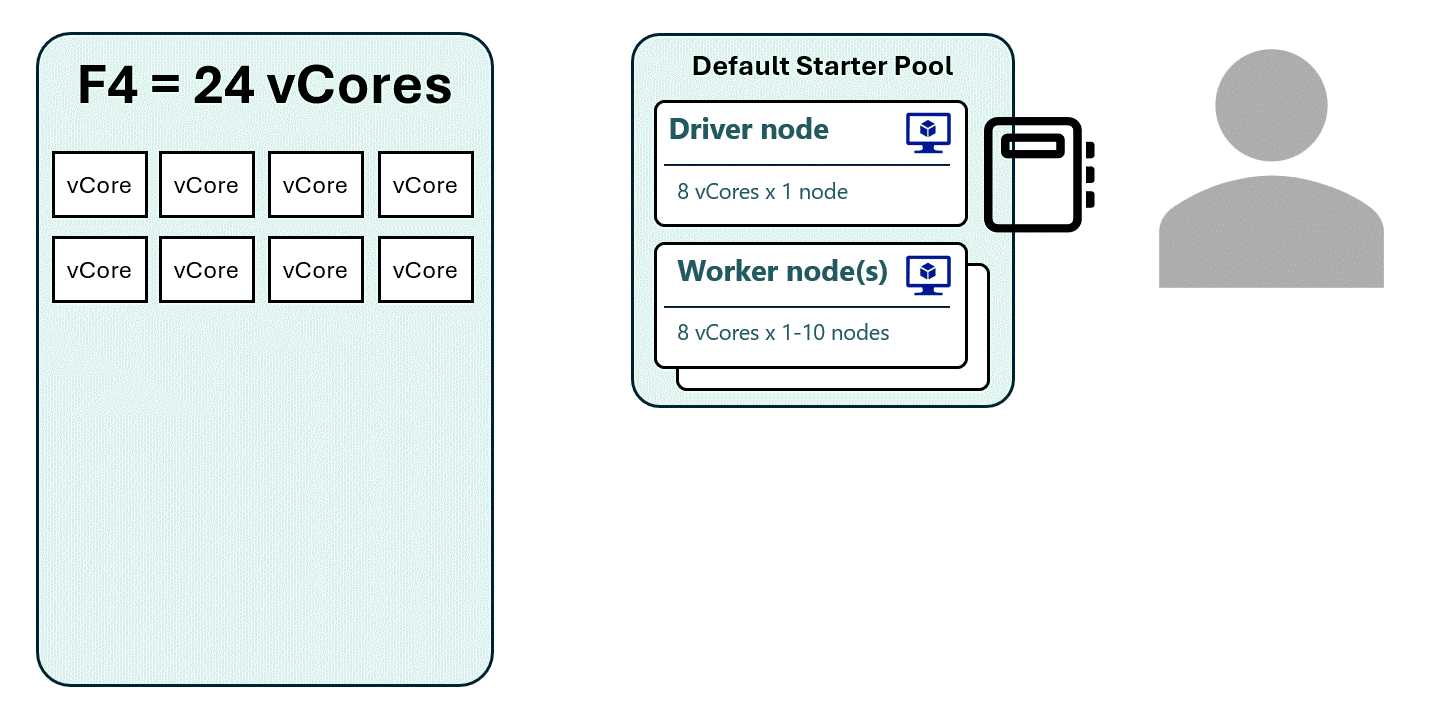
Understanding How Multiple Notebooks Use Capacity
In Part 1, we looked at the default Medium Size Starter Pool with autoscaling:
- Autoscaling: 1 to 10 nodes
- Each node = 8 vCores
- Default configuration starts with 1 driver + 1 worker = 16 vCores total
With this default setup, an F4 capacity can only run ONE active notebook session because each session requires 16 vCores.
Optimizing Multiple Spark Sessions on Limited Capacity
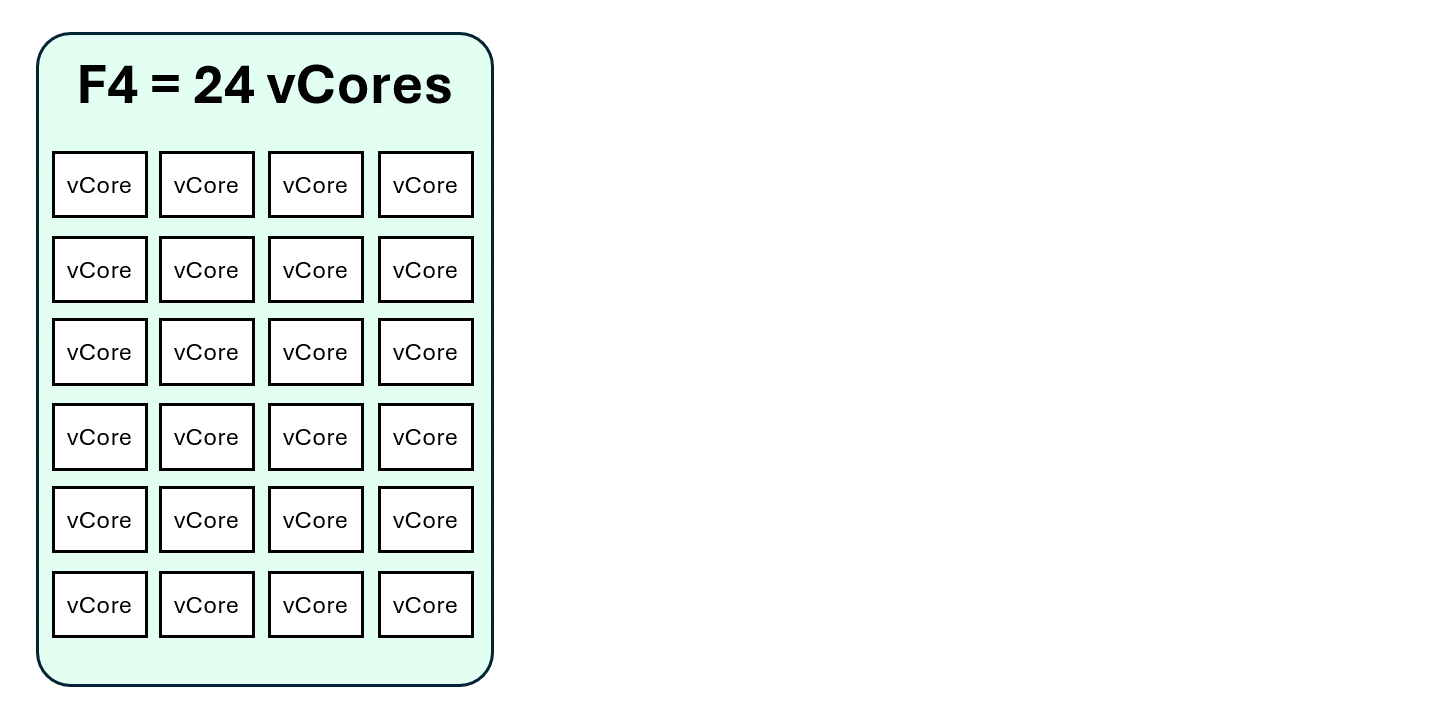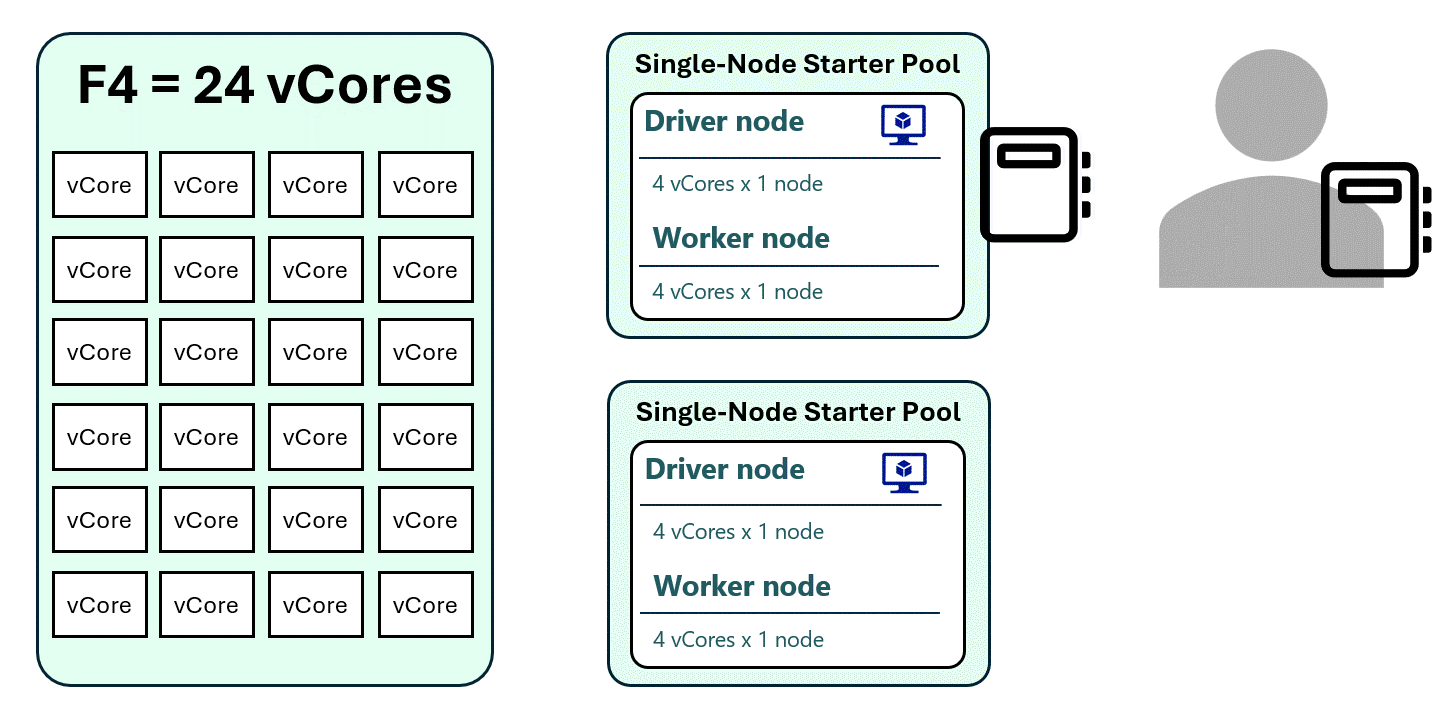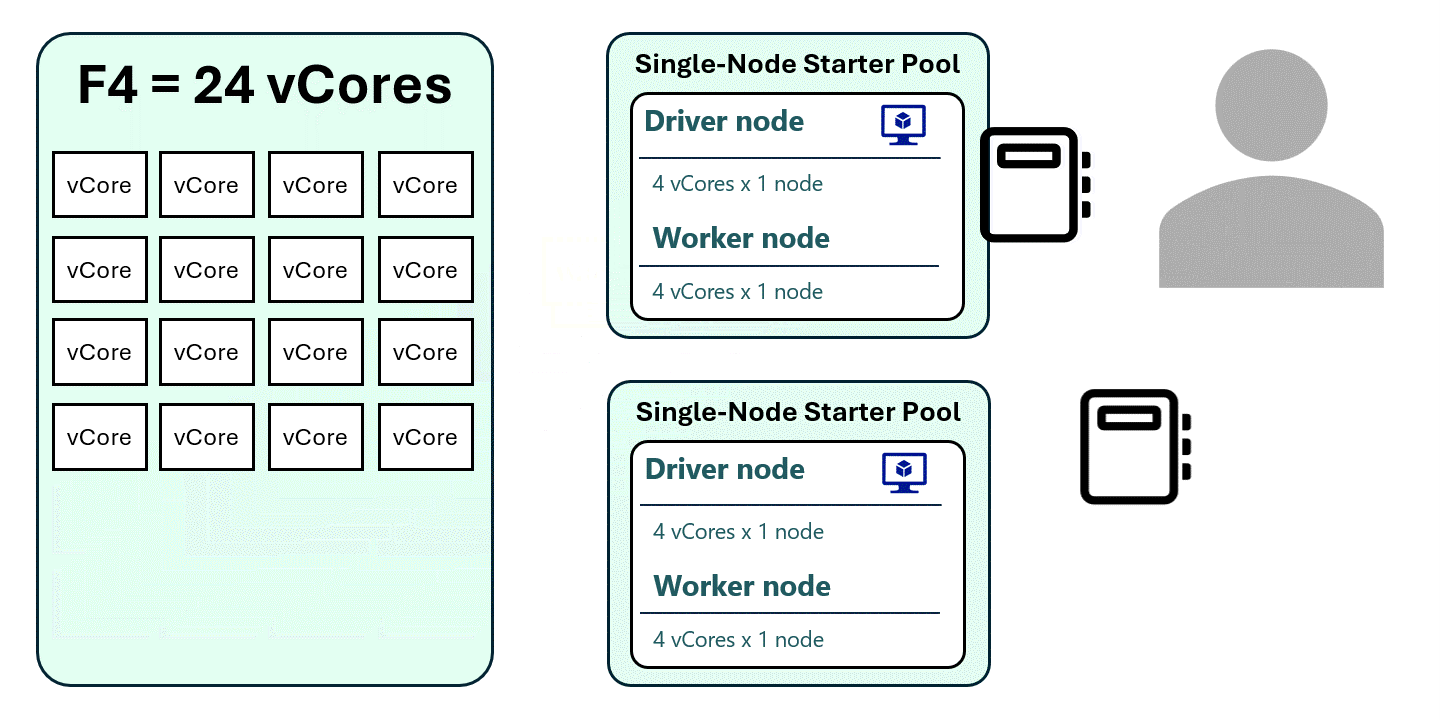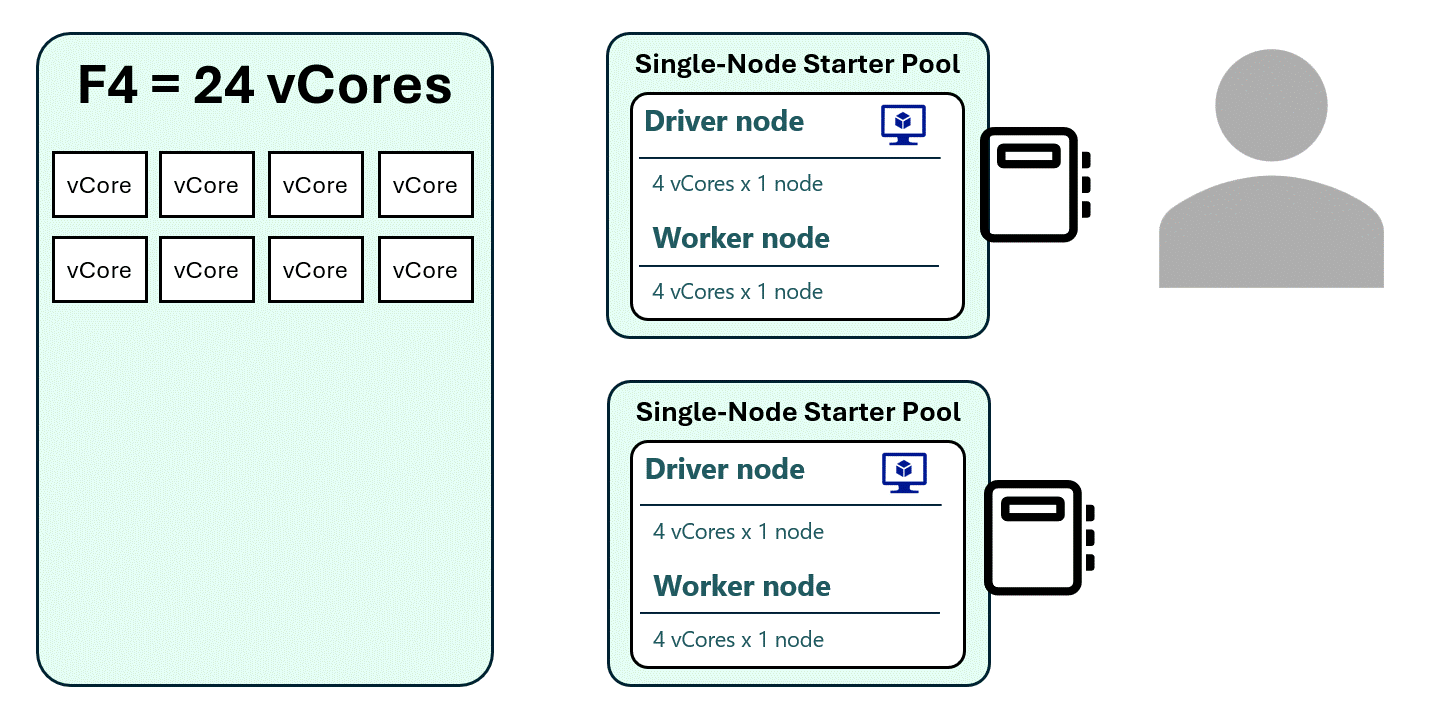
1. “Forcing” a Single-Node Spark Pool
By setting autoscale to 1 for both minimum and maximum nodes, the driver and executor run on the same node, reducing the vCore requirement.
- Each session now uses only 8 vCores
- An F4 capacity can now support up to 3 active sessions instead of just 1
2. Using a Custom Small Pool
Another option is to create a Small Pool, which is half the size of a Medium Pool.
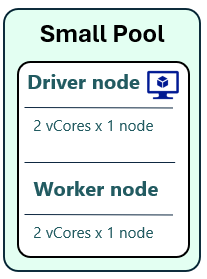
- A Small Pool, forced to 1 node, uses only 4 vCores
- An F4 capacity can now run up to 6 active sessions
Considerations:
- Limited compute power per session
- Longer startup time compared to Starter Pools
Why Does a Custom Spark Pool Take Longer to Start?
When choosing between Starter Pools and Custom Spark Pools, startup time is a key difference.
- Starter Pools are prehydrated live clusters, meaning Fabric automatically maintains idle compute resources for faster execution.
- Custom Pools must be fully spun up, which can take a few minutes.
For interactive workloads, using Starter Pools ensures fast startup times. For specialized workloads that require custom configurations, Custom Pools are necessary, but plan for longer execution start times.
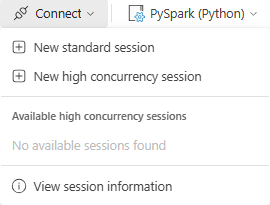
3. Using High Concurrency Mode
Another way to optimize capacity usage is to use High Concurrency Mode, which allows multiple notebooks to share the same Spark session instead of launching separate compute clusters.
Benefits:
- Reduces CU consumption by avoiding redundant session creation.
- Improves execution speed by attaching to an already running session.
- Allows up to five notebooks to share a single Spark session.
Limitations:
- High Concurrency Mode is user-specific—sessions cannot be shared across different users.
- All notebooks must use the same default Lakehouse configuration.
- Not suitable for scheduled workloads or multi-user scenarios.
To enable it, select “New high concurrency session” in the notebook toolbar instead of the default Standard Session.
For a deeper dive into High Concurrency Mode, including use cases and best practices, check out my next post: Optimizing Fabric Spark with High Concurrency Mode.
Another Trick: Using NotebookUtils RunMultiple
High Concurrency Mode allows multiple notebooks to share an interactive Spark session, but sometimes you need more control over execution order—especially when orchestrating multiple notebooks.
A useful alternative is NotebookUtils RunMultiple, which enables a parent notebook to trigger child notebooks within the same session. This works both for interactive scenarios and when scheduling jobs, reducing unnecessary session startups while ensuring efficient execution.
notebooks = {
"activities": [
{
"name": "Load Dimension Customers",
"path": "3_AquaShack_Load_Dimension_Sales_Customers"
},
{
"name": "Load Fact Sales Transactions",
"path": "4_AquaShack_Load_Fact_Sales_Transactions",
"args": {'useRootDefaultLakehouse': True},
"dependencies": ["3_AquaShack_Load_Dimension_Sales_Customers"]
}
]
}
notebookutils.notebook.runMultiple(notebooks)When using NotebookUtils RunMultiple, you can structure notebook execution as a Directed Acyclic Graph (DAG), ensuring that tasks run in the correct order while optimizing Spark session usage.
Unlike run(), which triggers notebooks one at a time, runMultiple() allows defining dependencies so notebooks execute in parallel or sequentially as needed.
Fabric Spark Job Queueing for Scheduled Notebooks
When you hit your compute limit, Fabric automatically queues scheduled jobs instead of failing them.
How Job Queueing Works
- The max queue limit is equal to the Capacity SKU size (e.g., F4 allows 4 jobs in the queue)
- Jobs in the queue will retry automatically when resources become available.
- Queueing only applies to scheduled notebook jobs (triggered via Pipelines or Scheduler).
- Interactive notebooks do not queue—they return an error instead.
Example Scenario: Reaching Capacity Limits
Let’s say you’re using an F4 capacity (8 Spark vCores, burstable to 24 vCores):
- You schedule 5 Spark notebooks to run at the same time.
- Each Medium Starter Pool session requires 16 vCores.
- Only one notebook can run at a time, because even with bursting, the F4 capacity cannot handle more.
- The remaining 4 notebooks are placed in the queue and will execute in order of submission as resources become available.
Trial capacities do not support queueing (queue limit = 0).
Once queued, a job’s status appears as “Not Started” in the Monitoring Hub, changing to “In Progress” when it starts executing.
Key Takeaways & Tips
To optimize Spark usage on limited capacity, consider:
- Using a Small Size Cluster (half the resources of Medium).
- Configuring auto shut-down to prevent idle CU burn.
- Using High Concurrency Mode to share sessions across notebooks.
- Using NotebookUtils RunMultiple for scheduling without extra compute.
- Planning around queueing limitations—interactive jobs do not queue.
Final Thoughts & What’s Next
Managing multiple Spark notebooks on the same Fabric capacity requires careful resource management. By understanding bursting, concurrency modes, and job queueing, you can optimize capacity usage and avoid hitting compute limits.
This is Part 2 of my Fabric Spark series. Next, I’ll be diving into High Concurrency Mode in Fabric Spark—exploring how it works, when to use it, and how it helps optimize CU consumption.
The upcoming post will cover:
- How High Concurrency Mode allows multiple notebooks to share a session
- When to use it over Standard Sessions
- Best practices for improving capacity efficiency
- Limitations and potential pitfalls
If you found this post helpful, let me know—how do you manage multiple Spark workloads in Fabric?
Pingback: Optimizing Fabric Spark with High Concurrency Mode – justB smart
Pingback: Fabric Spark Notebooks and CU Consumption – justB smart
Comments are closed.