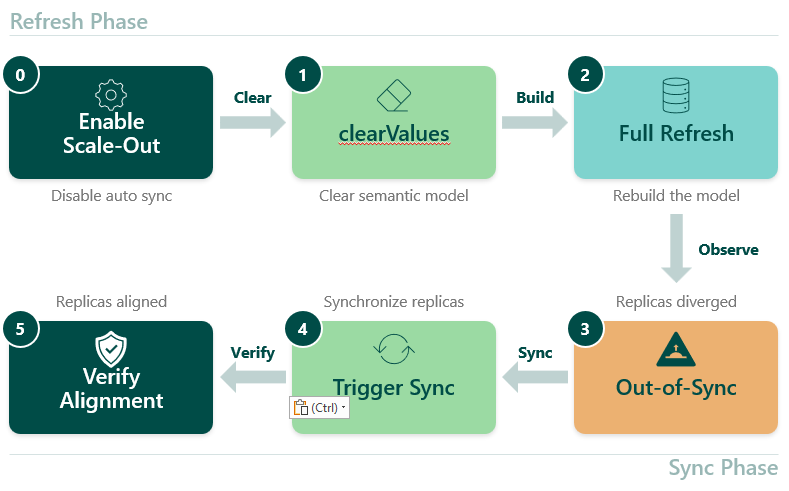
Dette indlæg har stået på min liste i snart tre år, så nu er det vidst på tide jeg får det skrevet. Alle Microsoft BI udviklere har nemlig krav til denne information, da vi som udgangspunkt alle hader at dokumentere og elsker at automatisere trivielle opgaver ![]()
Skal skynde mig at tilføje, at alt kredit går til Alex Whittles fra det engelske BI konsulentfirma Purple Frog. Jeg deltog tilbage på SQLBits VIII til hans session om “Automating SSAS cube documentation using SSRS, DMV and Spatial Data“, hvorefter jeg begyndte at bruge den kode han lagde tilgængelig på sin blog. Har implementeret det med stor succes ved en håndfuld virksomheder.
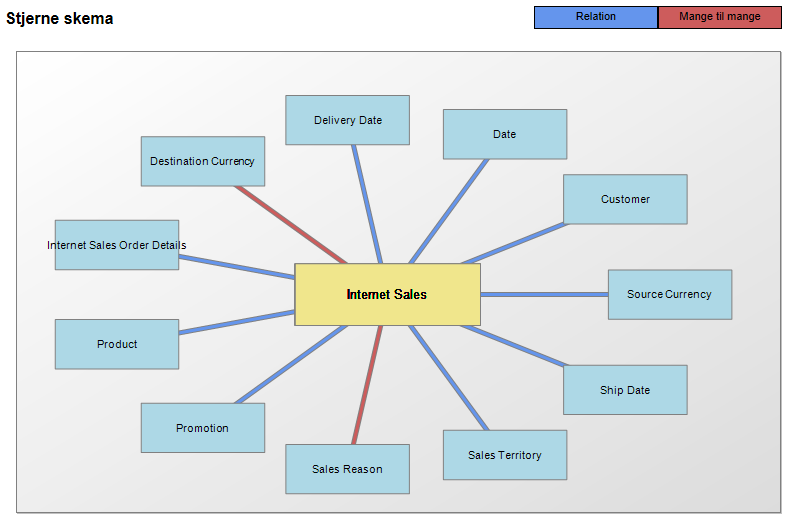
Det går i alt sin enkelthed ud på at trække metadata ud af kuben via de DMV’ere som er tilgængelige, hvorefter det kan præsenteres i en række SSRS rapporter, som er indbyrdes linket sammen. Som en cool detalje er “Dimension Usage” vist grafisk i stjerne skema – tegnet via den map engine der ligger i SSRS. Der er nok ikke mange, som er klar over, at det faktisk er en tegne motor. Allan har skrevet et mere detaljeret indlæg om dette emne “Drawing a logo or diagram using SQL spatial data“.
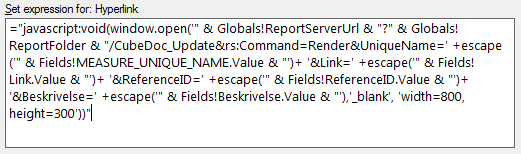
Jeg har foretaget en række udvidelser af udtræk og rapporter, hvor den største er muligheden for at tilknytte kommentarer til de forskellige elementer direkte via rapporterne. Der er til hver objekt indsat et lille edit-ikon, som via en action og lidt javascript åbner en lille rapport i et pop-up vindue.

Det som angives i parameter-input bokse bliver via en stored procedurer gemt i en tabel ved klik på “View Report”. Der anvendes et merge-statement, så det er muligt også at foretage rettelser.
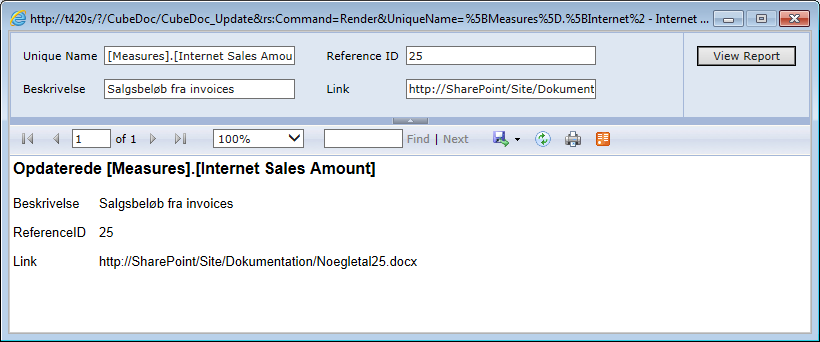
Indrømmet – det er lidt en høker løsning, men det er smart at have præsentation og indtastning samlet i den samme “applikation”. Alle objekter i kuben har unikke navne, så det er meget simpelt at gemme i beskrivelser af dimensioner, attributter, measures m.m. i den samme tabel. Har i et tilfælde udvidet, så der udover beskrivelse, reference id og link også er mulighed for at angive den primære kilde – herunder kildesystem, tabel og felt.
Når jeg har præsenteret denne løsning har flere foreslået, om jeg ikke skulle lave noget write-back til kuben, så beskrivelserne ikke kun er tilgængelige via rapporterne. En rigtig god ide, som burde kunne laves via lidt xmla. jeg har dog valgt ikke at gå videre med det, af den simple grund, at Excel ikke formår at vise “Descriptions” fra measures.
Af andre udvidelser jeg har lavet, kan nævnes visning af “attribut properties” under dimensionerne. Endvidere har jeg i BUS matice og stjerne-skemaer tilføjet markering af mange-til-mange relationer. Denne type relation kan være en virkelig dræber for query performance og derfor rar, at være lidt opmærksom på.
En anden lille detalje er tilføjelse for mulighed for at skjule/vise “hidden” objects, som i nogle tilfælde er fine at kunne se og andre tilfælde bare støjer. Derudover har jeg i rapporten med measures taget de expressions der angiver aggregering- og data type og ført tilbage i stored procedurer.
Slutteligt kan nævnes, at jeg netop nu sidder med et projekt, hvor jeg gemmer de meta-data der udtrækkes, så det er muligt at sammenligne kubens udvikling over tid samt danne sig et overblik over forskelligheder mellem miljøer. konkret handler det om at foretage automatisk unit test af kuber, hvilket jeg holder indlæg om på MsBIP møde nr. 18 og SQLSaturday #275.