Jeg havde lørdag d. 29. marts fornøjelsen at præsentere mit indlæg om automatiseret test af kuber på SQLSaturday #275, der blev afholdt i Microsofts lokaler i Hellerup. Et helt fantastisk arrangement, som jeg håber kan blive en tradition.
Mit indlæg har rod i en konkret kundeopgave, hvor der var behov for at automatisere test af en forholdsvis stor og kompleks kube, som var en del af et udviklings-setup med release hver tredje uge. Helt simpelt har jeg udviklet en metode til at udtrække snapshot af både kubens struktur (metadata) samt selve indholdet (data). Snaphot kan således fortages både før og efter deployment og derefter sammenlignes. Det er dog også muligt at sammenligne på tværs af miljøer eller henover tid ved f.eks. at foretage snapshot dagligt.
Kubens metadata eksponeres via en række DMV’er – f.eks. giver “SELECT * FROM $SYSTEM.MDSCHEMA_MEASURES” en liste over alle measures i kuben med et utal af properties. Ved at opsætte en LinkedServer kan det via en OpenQuery forespørgsel relativt simpelt gemmes i en tabel og wupti, så kan der opsættes en rapport som synligøre forskelle mellem to forskellige snaphot. Tilsvarende kan opsætte via andre DMV’er, så metadata for dimensioner, attributter, measuregroups m.m. kan sammenlignes.
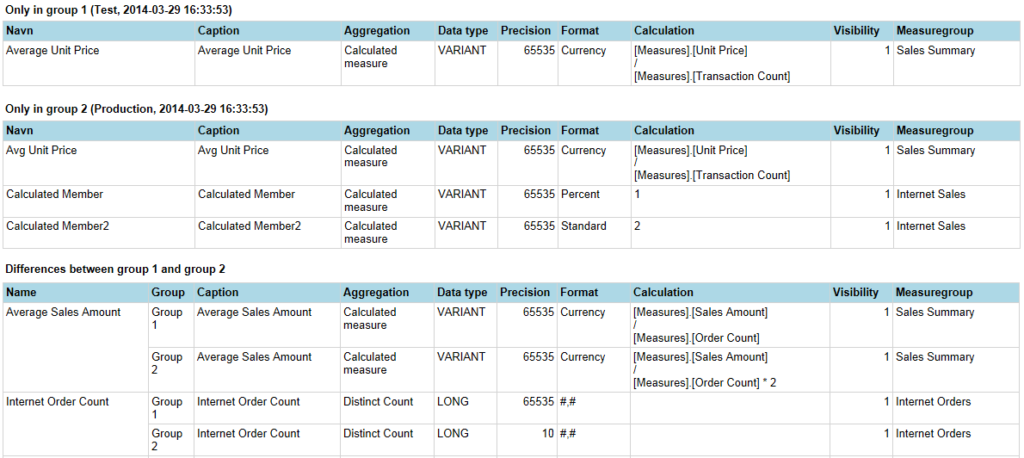
Samme metode med OpenQuery og LinkedServer kan anvendes til udtræk af data, som dog kun kan blive et udsnit – men hvordan udvælges et repræsentativt udsnit? Og hvordan håndteres, at data helt naturligt ændrer sig over tid? I min konkrete opgave valgte jeg at udtrække data for alle measures over flere forskellige tidsperioder (32 dage, 13 måneder og 5 år) filtreret på en anden gennemgående dimension. MDX forespørglen er opsat forholdvis dynamisk med flere forskellige parametre – f.eks. med en offset dato, så der kan udtrækkes data tilbage i tiden. Listen over measures i kuben kan fåes via enten metadata snapshot eller via “Measures.AllMembers” – bemærk dog at Measures.AllMembers kun giver de synlige measures og at en liste via metadata kan blive meget lang og dermed få forspørgslen til at overstige begrænsningen på 8000 tegn.
Via en række linked rapporter kan eventuelle forskelle mellem snapshot synliggøres og om der findes et mønster – er det kun enkelte measures og/eller på konkrete tidsperioder?
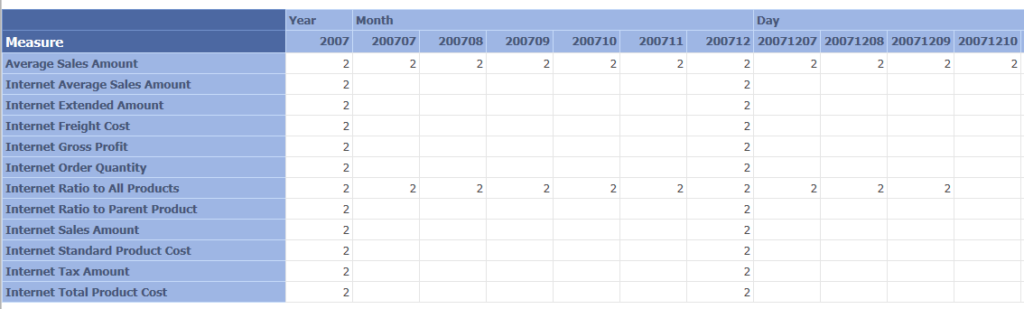
Til demo for mit indlæg har jeg opsat eksempel på AdventureWorks kube databasen deployed på to forskellige instanser, hvor jeg har jeg ændret i både struktur og indhold i kuberne. Jeg har uploaded både slides og demo-filerne, så I selv kan afprøve metoden. Jeg har kun tilpasset et udsnit af min kundeopgave til at virke på AdventureWorks, så der er uden tvivl behov for at tilpasse og udvide, hvis det skal anvendes professionelt ![]()
Foruden min egen udviklet metode, har jeg også med succes anvendt Microsoft BI test frameworket NBi, som har sin klare styrke i at teste dele af kuben. Det er en udvidelse til NUnit, hvor der kan opsættes test-cases via xml-syntax – f.eks. teste antal af members i en specifik attribut, performance på afviklingen af en specifik mdx eller sammenligne små resultatsæt. En anden styrke er at der kan opsættes tresholds – f.eks. at antallet af members skal ligge mellem 15 og 25 eller værdien af et measure skal være mellem 0 og 1. Perfekt til at teste at de ændringer man ligger i produktion er slået rigtigt igennem.
Begge disse løsninger komplementere hinanden godt, men kan også fint anvendes uafhængigt. Tjek begge ud og se hvad der passer i dit/jeres setup.