All the Data Factory templates that comes as part of my Power BI Monitor GitHub repository can already easily be imported and used with Synapse Analytics. So, why do I now create a new one?
The answer is simple. To get rid of a ridiculous constrain to an Azure SQL Database, that I used in a Lookup activity to create the batches of workspaces. This constrain is perfectly fine if you want to ingest the data to an Azure SQL Database, but not if your target is a Data Lake. Then we can instead take advantage of the SQL Serverless Engine that is part of Synapse Analytics to do the exact same job.
Get started with these four steps:
- Linked Service to the Power BI Rest endpoint
- Linked Service to the SQL Serverless endpoint
- Download and import Integration Pipeline template
- Adjust parameter for Storage Account
First you need to create a Linked Service to be able to call the Power BI admin APIs. The Linked Service is pretty straightforward, but the authentication can be a little tricky. The configuration is covered as part of my “Extracting the Power BI activity log with Data Factory” blog post.
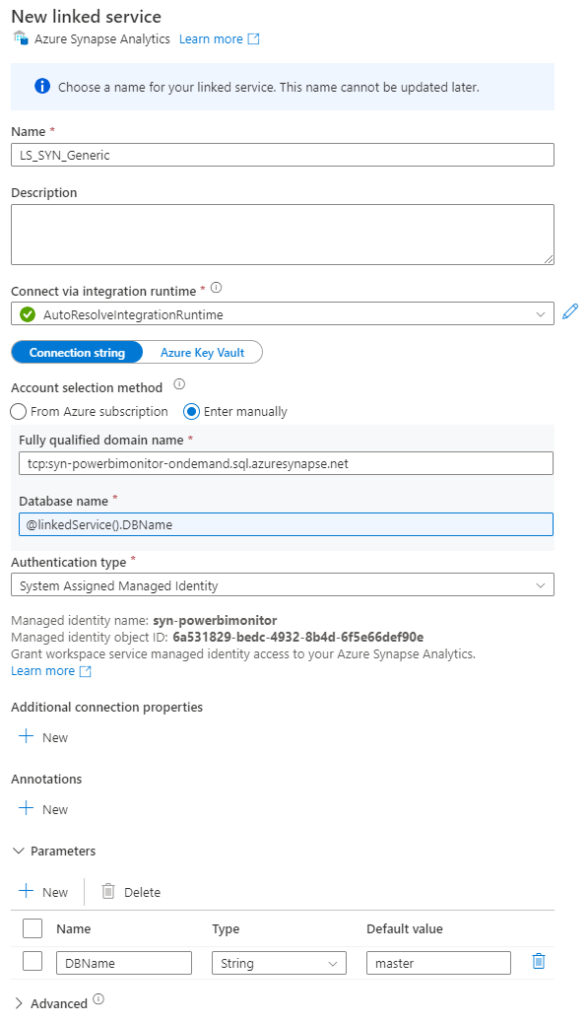
Secondly you need to create a Linked Service for the SQL Serverless endpoint. There is already pre created a default linked service for this Synapse SQL Server – but that’s for the Dedicated SQL Pool and we don’t want to use that. For the same reason you cannot select it, and will need to manually enter the fully qualified domain name of your own endpoint. It’s the name of your Synapse Workspace followed by -ondemand.sql.azuresynapse.net. To future prof the Linked Service, I created a parameter for the Database name. It’s not used for this specific pipeline. Authentication should be set to the System Assigned Managed Identity.
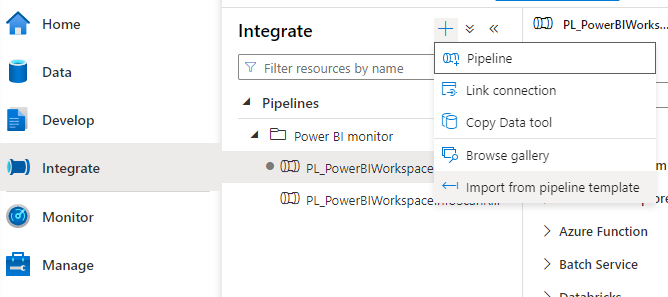
And now your can go ahead and download the pipeline template. It’s a zip file, that you then need to import under the “Integrate” tab.
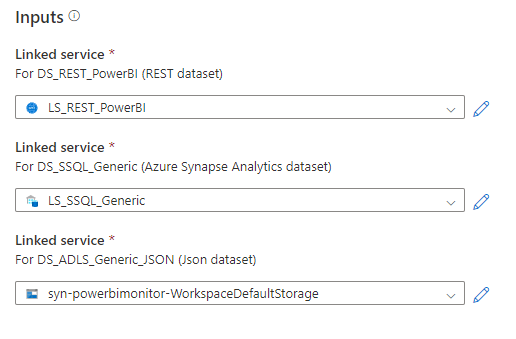
And then simply point to the Linked Services. Be sure to select the newly created Azure Synapse Analytics and then just use the default for the Data Lake Storage.
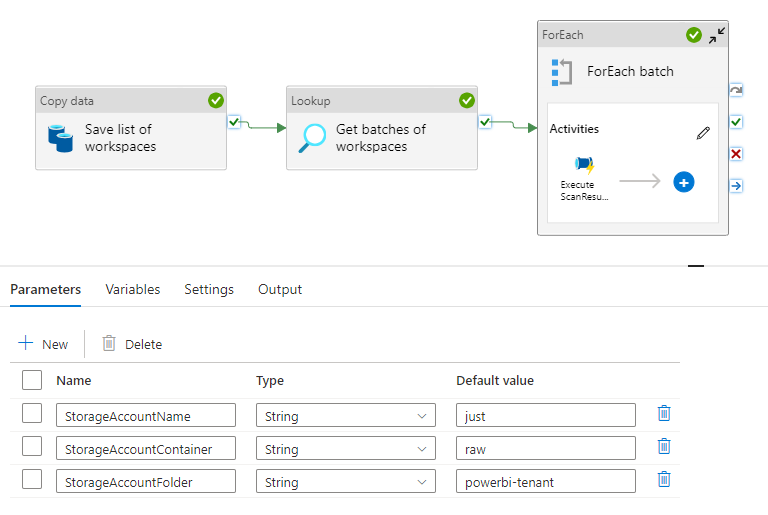
And talking about the Data Lake Storage, then you need to specify the name of your own storage account in the StorageAccountName pipeline parameter. This is used as part of the Lookup activity when fetching the workspacelist that is saved as a json file in the first activity. You can also specify the container and folder, where the files should be placed. I used “raw” and “powerbi-tenant”.
Have fun using the pipeline. If your curious for learning more of the setup, then I recommend you to read “Extracting Power BI metadata with Data Factory (part 1)” blog post.
I will show how to query the data with Synapse Serverless SQL in an upcoming blog post.
Pingback: Query Power BI tenant metadata with Synapse Serverless SQL – justB smart
Pingback: Extension to the Scanner API – justB smart