As a natural continuation on my latest blog post on Extracting the Power BI activity log with Data Factory i will now share how to extract all the metadata of your Power BI tenant. Information on workspaces, datasets, reports, datasources etc so you can visualize and get insight on the full catalogue + use it in combination with the activity logs ?
Recently Microsoft released four new “WorkspaceInfo API’s” that lets us get this information in a easy way compared to the “old” method, where we had to call a API for each type of information looping over all the workspaces in the tenant. This new WorkspaceInfo API also exposes information not found in any other API – this is lineage, endorsement details and sensitivity labels. I therefore believe my solution is pretty cool as nobody have shown similar PowerShell solutions – yet ?
The reason why we have four new API’s is because it’s called asynchronously and with a maximum of 100 workspaces for each call:
- GetModifiedWorkspaces: Get full list of all workspaces in your tenant or modified workspaces since a specified date
- PostWorkspaceInfo: Initiate a call to receive metadata for the requested list of workspaces (max 100)
- GetScanStatus: Gets status for the initiated request
- GetScanResult: Gets result for the initiated request. This is all where we get all the metadata.
So now to the fun stuff. Using the REST API’s with Azure Data Factory. I reuse the linked services and datasets that I setup with the pipeline to extract the activity events. First I get the full list of workspaces – this includes the old ones (groups), the new ones (workspaces) and also all personal workspaces. With the GetModifiedWorkspaces, you have no way to distinguish the three different types – you just get a long list of workspace id’s.
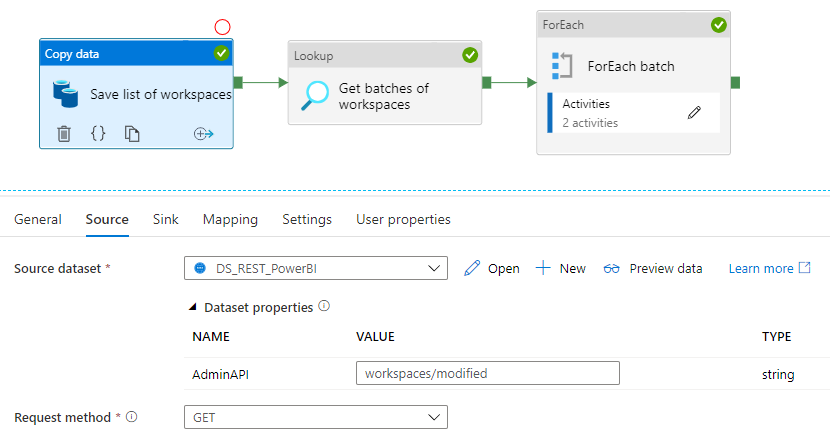
I have chosen to save the list to a Azure SQL database, as I can then use my T-SQL skills to create “batches” of 100 workspaces, which is required for the PostWorkspaceInfo API. This API also want the list in a slightly other format than returned from the first API. I would love to hear if someone can achieve the same, but with the build in expressions and function in Data Factory and then omit having to land the data in SQL. Because this is not an optimal dependence, if you will save the final results in a Blob Storage or Data Lake.
To create and get the “batches” I use a lookup activity pointing to the Azure SQL Database with this query:
WITH [WorkspaceRanked]
AS
(
SELECT ROW_NUMBER() OVER (PARTITION BY [ADF_PipelineRunID] ORDER BY [Id]) AS [Rank]
,[Id]
,[ADF_PipelineRunID]
FROM [stgpowerbi].[ModifiedWorkspaces]
),
[WorkspaceBatched]
AS
(
SELECT ROW_NUMBER() OVER (PARTITION BY([Rank] % 100), [ADF_PipelineRunID] ORDER BY [Rank] ASC) AS [Batch]
,[Id]
,[ADF_PipelineRunID]
FROM [WorkspaceRanked]
)
SELECT N'{"workspaces": ["' + STRING_AGG([Id], '", "') + '"]}' AS [BodyExpression], [Batch]
FROM [WorkspaceBatched]
WHERE ADF_PipelineRunID = '@{pipeline().RunId}'
GROUP BY [Batch]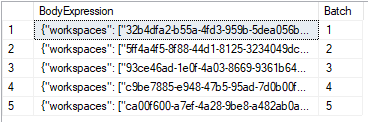
I build up the exact string, that has to go into the body of the PostWorkspaceInfo API and a batch number for each 100 workspaces. In the tenant, where I tested my solution there are nearly 500 workspaces and then the result looks like this:
Next up is initiating a foreach activity for each of the batches to get the data ready for extraction. This is the asynchronous part, where we have to use a until activity to get the status of the request. Unfortunately Data Factory have a limitation, so you can’t use a until inside a for each. Therefor I have broken this logic out in it’s own pipeline with these activities:
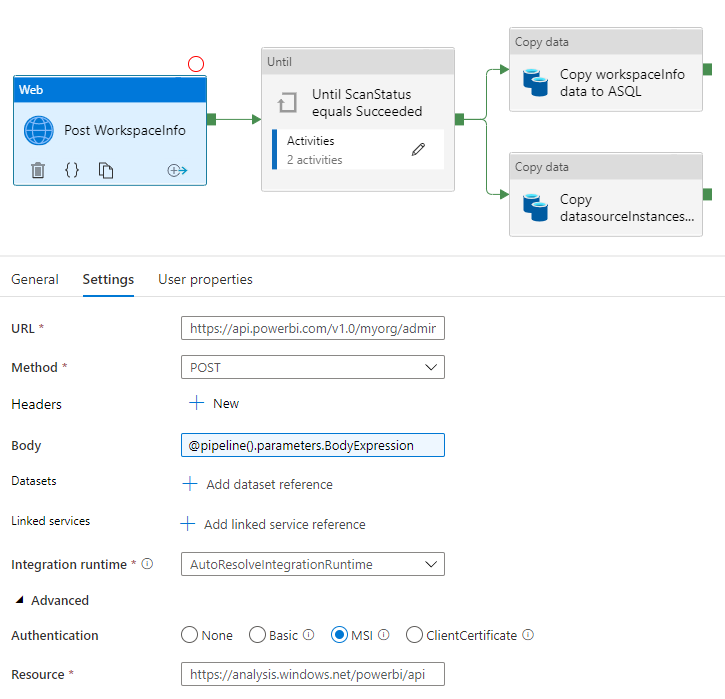
I get the Body Expression passed in as a parameter and then use a Web activity to initiate. Luckily we can also use the MSI authentication method here, so we can get a very simple security setup without the hassle of dealing with an APP registration and Token generations.
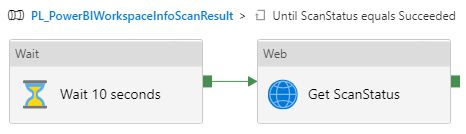
The until activity was two activities. First waiting 10 seconds and then checking the status with a API call to GetScanStatus. This continues until the status equals “Succeeded”. In my experience it does that already in the first run, but you might see other results and may therefore lift the wait to 30 seconds or higher.
Lastly we go grab the data with a copy activity calling the GetScanResult API as the source dataset. In my solution I insert the data in a Azure SQL Database – going from JSON structure to a relational structure with mapping setup on the different nodes. This gives me some trouble as there are two arrays returned. One with Workspace information and another with Datasource information. So I decided to call the API twice and thereby stage this information in two different tables. You can do the same when staging the JSON directly to Blob Storage or Data Lake or you could just use one copy activity and then save a few pennies in the cost of running the pipeline. Here you can see how I setup the mapping in one of the copy activities:
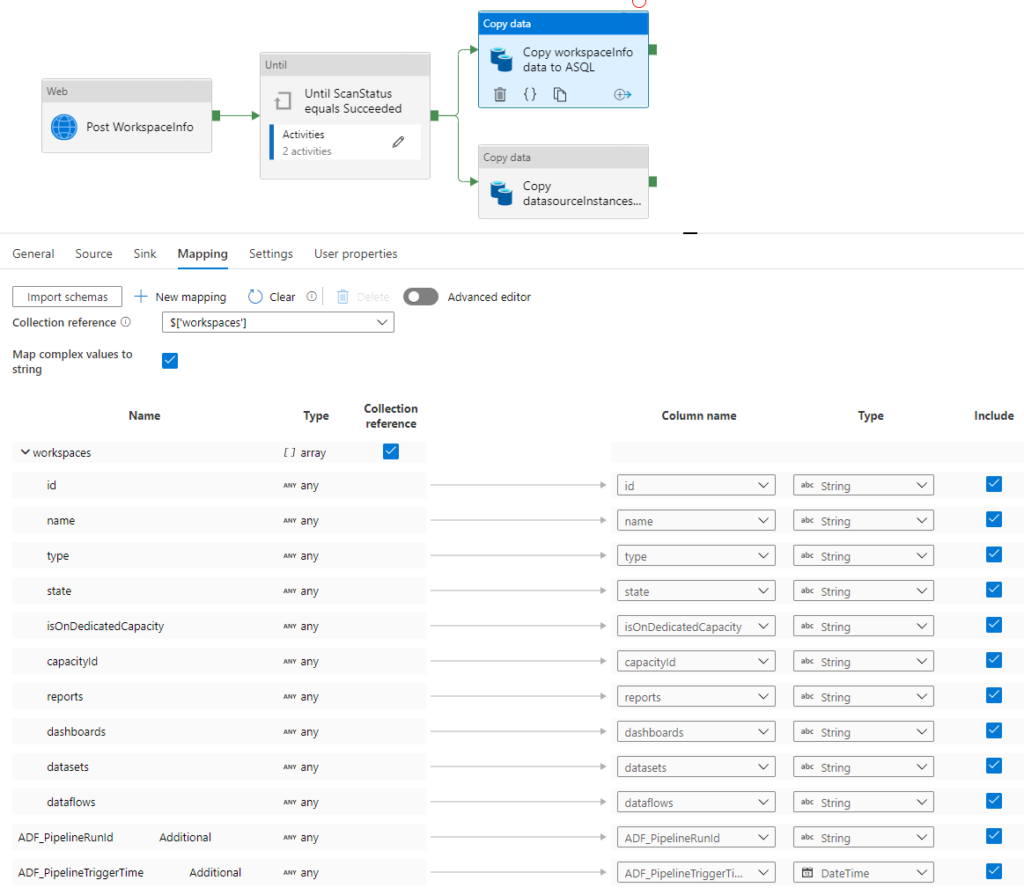
This means that I still have to deal with JSON structure in the SQL Database, but that’s not really a problem because we have functions like JSON_VALUE and OPENJSON. Here is a SQL query to retrieve a list of all the reports in the tenant including information on when it was created, modified and by who.
SELECT [wi].[id] AS [workspaceId]
,CAST(JSON_VALUE([r].[value], N'$.id') AS nvarchar(100)) AS [reportId]
,CAST(JSON_VALUE([r].[value], N'$.name') AS nvarchar(100)) AS [reportName]
,CAST(JSON_VALUE([r].[value], N'$.datasetId') AS nvarchar(100)) AS [datasetId]
,CAST(JSON_VALUE([r].[value], N'$.createdDateTime') AS datetime) AS [createdDateTime]
,CAST(JSON_VALUE([r].[value], N'$.modifiedDateTime') AS datetime) AS [modifiedDateTime]
,CAST(JSON_VALUE([r].[value], N'$.modifiedBy') AS nvarchar(100)) AS [modifiedBy]
,[wi].[ADF_PipelineRunId]
FROM [stgpowerbi].[WorkspaceInfo] AS [wi]
CROSS APPLY OPENJSON([wi].[reports]) AS [r];I have added the pipeline to GitHub in two versions so you can get an easy start whatever you would land your data in a Azure SQL Database or a Azure Data Lake. Be aware that the pipeline templates also includes the datasets and you will then get duplicates if you also imported my “activity event” pipeline template. That’s because I love to create generic datasets and therefore you will need to make some clean up after importing.
- https://github.com/justBlindbaek/PowerBIMonitor/raw/main/DataFactoryTemplates/PL_PowerBIWorkspaceInfo_ASQL.zip
- https://github.com/justBlindbaek/PowerBIMonitor/raw/main/DataFactoryTemplates/PL_PowerBIWorkspaceInfo_ADLS.zip
This ends my blog post – or at least the first part of the journey to get all the metadata from your Power BI tenant. Although the new WorkspaceInfo API is great, it miss some important information that we thankfully can get in the “old” API’s. That is:
- Users in the Workspaces and their access level
- List of Capacities
Therefore, the serial continues… go on and read part two ?
Pingback: PowerBIQuiz: APIs & PowerShell - Benni De Jagere
Pingback: Extracting Power BI metadata with Data Factory (part 2) – justB smart
Awesome article. Really saved lot of my time
I am using synapse workspace and how to reuse the solution you placed in github without me developing from scrach.
Great blog series thank you!!
Is there anything similar we can do to get the information on reports, datasets, dashboards, etc. in a tenant?
Thanks 🙂
This solution is getting it all out 🙂 Or maybe I don’t get your question?
Great solution. But how can I adjust the schema in the mapping if I additionally query the users via the POST API. Unfortunately it does not work via schema import.
Hi Alexander. I will suggest you make the change in the advance editor of the mapping. Here you simply create a new mapping named users. Make sure to also create the users column in the destination table.
Hoped this helps?
Pingback: Extracting Microsoft Graph data with Data Factory – justB smart
Pingback: Extracting Power BI tenant metadata with Synapse Analytics – justB smart
Any idea what determines whether a workspace is considered modified? I am curious whether this includes RLS changes, workspace role changes (new user, change or permissions), change of labels etc. Would like to assume it is any and all attributes of the workspace and all its artifacts but can’t see any hard evidence. Short of testing every possibility, hoping maybe you have seen something documented that I missed.
Unfortunately I don’t know the specifics. Did your testing reveal anything that you would like to share?