As a natural follow-up on my last blog post about using Synapse Analytics to extract a complete tenant catalogue of Power BI metadata I will now show how to use the power of the Serverless SQL Pool to query all the wonderful data.
As you might know, the data is extracted in the semi-structured JSON format, that is very flexible as the schema can change over time when Microsoft extends the API and adds more metadata. But for reporting and analysis we will need a more fixed and flattered schema – and this is where we can use the Serverless SQL. We can simply add a relational SQL endpoint directly on top of the files with the use of SQL views.
As always – I have published the code on my PowerBIMonitor GitHub repo. Here you will find a new folder called ServerlessSQL that contains a single SQL script (Create database and schemas.sql) and a folder (raw) with a query for each of the artifact types:
- Dashboards.sql
- DashboardTiles.sql
- Dataflows.sql
- Datamarts.sql
- Datasets.sql
- DatasourceInstances.sql
- Reports.sql
- Workspaces.sql
You will start with creating a database and the schema we will use for the 8 views.
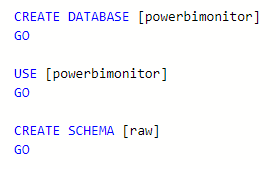
The views all contain a reference to the storage account containing the extracted JSON files. You will need to replace [StorageAccountName] with the name of your own. Also check if the location it correct – you might have changed it in the Integration Pipeline.

All the views is what will be considered as base views. You will most likely do some additional transformations to get it into a proper star-schema with facts and dimensions. I would gladly hear your input on how to create the datamodel as it can be created in many many different ways depending on the type of reporting and analysis you will be doing:
- Is it enough with the latest version of the extracted metadata?
- Or do you want dimensions with type 2 changes?
- Need to count number of the different artifacts over time?
- Need to count and/or show users over time?
- Other requirements?
As an example you here see the base query for the datasets and how it’s build up with multiple CROSS APPLY’s to unfold the different levels of the JSON file. Checkout how I get the Endorsement and CertifiedBy attributes that are contained in a property. With the DatasourceInstanceId I only get the first from the array.

Beware that these base views is having full history and most of them are doing a CROSS APPLY on the users. This means that one given artifact is represented multiple times. Also note that I have not included the unfold of the lineage information that you can get with the upstreamDataflows and datasourceUsages.
I have also not included the datasetExpressions and datasetSchema as this require a change of tenant settings before you can extract it. It’s pretty straight forward if you have access to the Admin center – and then you need to change the URI parameter on the Integration Pipeline.
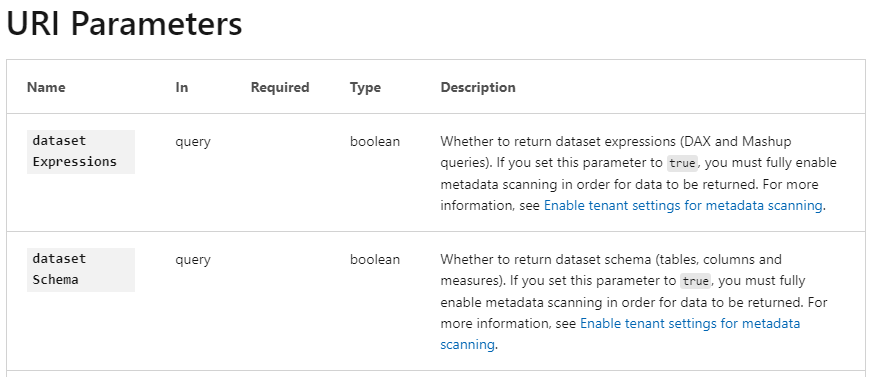
My next blog post will show how to query the Activity Events. Same idea, but there are some challenges as Microsoft is not providing the full schema and it’s constantly evolving with more and more attributes.
Pingback: Extracting Power BI tenant metadata with Synapse Analytics – justB smart
Pingback: Query Power BI activity events with Synapse Serverless SQL – justB smart
Pingback: Extension to the Scanner API – justB smart